Claude Code’s massive source code got leaked: everything you need to know
The internet has been going absolutely wild with the massive unprecedented leak of Claude Code’s entire source code.
It wasn’t a hack, intrusion, or model theft.
It was a fatal release mistake.

Anthropic accidentally included internal debugging files in a public package, which exposed a large portion of Claude Code — all the essential code that turns Claude into a specialized CLI coding assistant.
They said it was “release packaging issue caused by human error”, and that no user data, API keys, or Claude model weights (Opus, Sonnet, etc.) were exposed. What leaked instead was the “harness” — the product logic around the model.
The models weren’t leaked — but still a crucial part of the playbook for building a production AI coding agent largely was.
1. A 60MB debugging mistake — how it happened
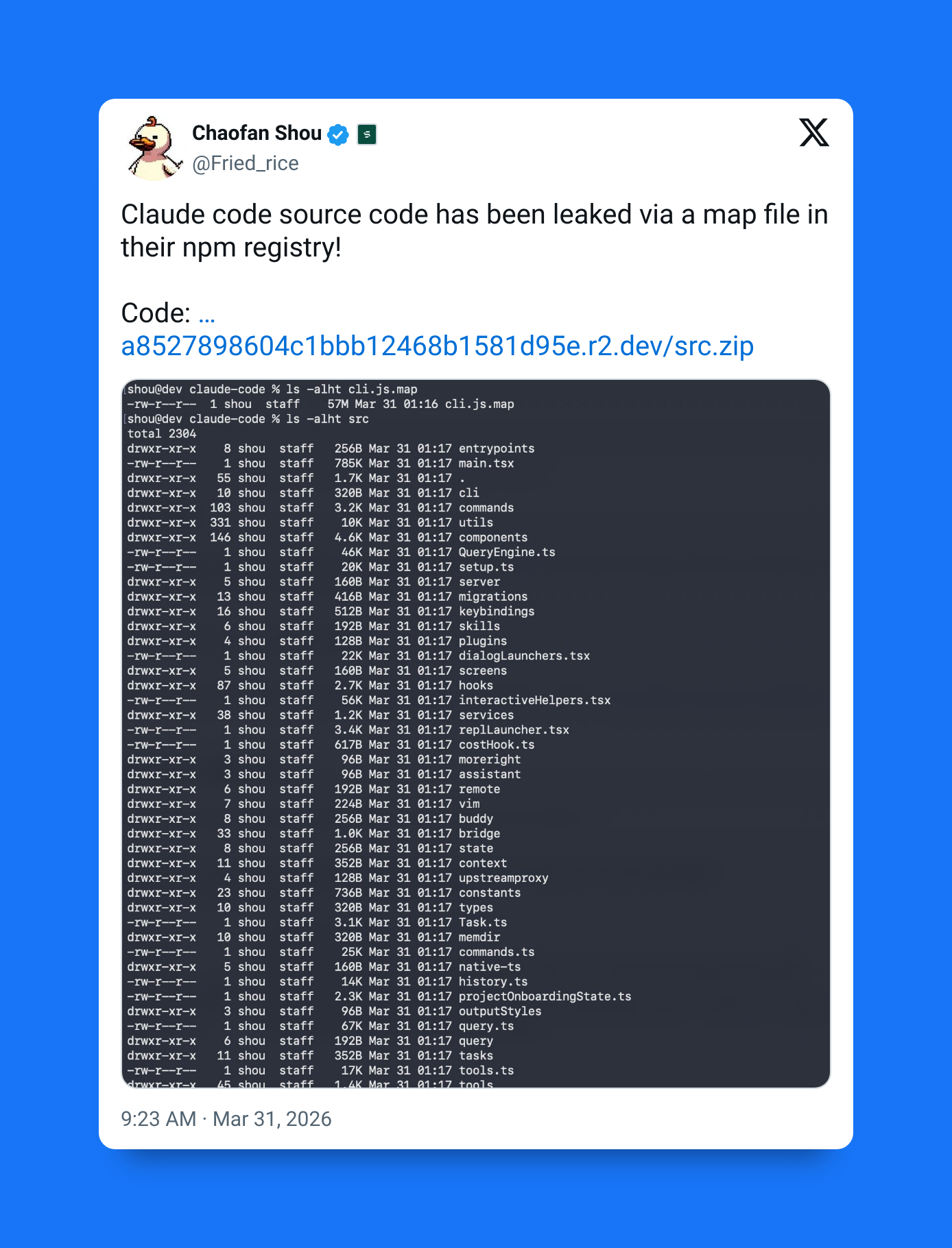
The leak originated from npm release @anthropic-ai/claude-code version 2.1.88.
Instead of shipping only compiled production code, the package accidentally included source map (.map) files, which are meant for debugging. These files map minified code back to the original source.
cli.js.map was leaked in version 2.1.88:

In this case, the source map:
- Was roughly 60MB
- Contained references to original uncompiled TypeScript
- Pointed to a public, unauthenticated Cloudflare R2 bucket
- Exposed the entire internal Claude Code source
So the leak wasn’t a breach — the source was effectively handed out with the release.
The irony
Claude Code is built on Bun, the JavaScript runtime Anthropic recently acquired.
A known Bun issue reportedly allowed source maps to be included in production builds even when disabled.
This is not confirmed as the root cause — but it likely contributed to the packaging mistake.
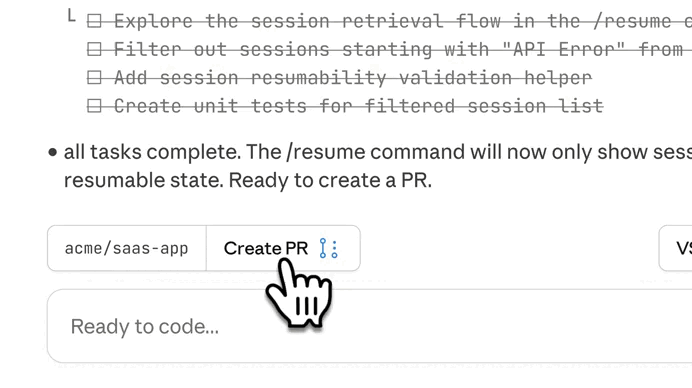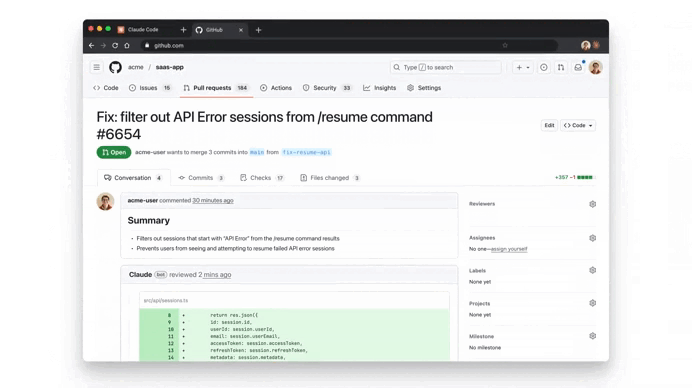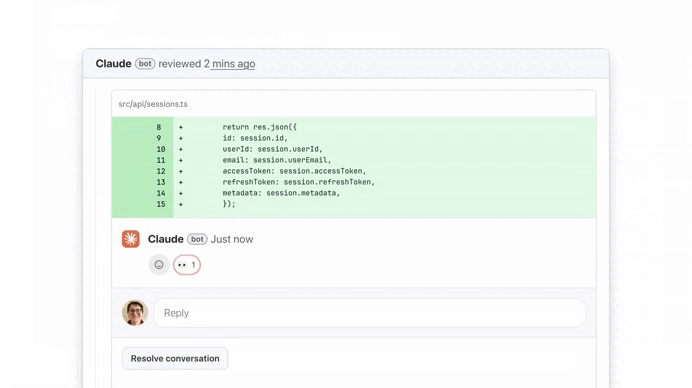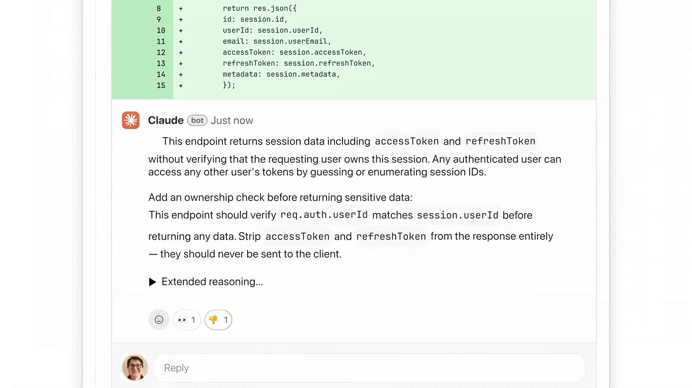
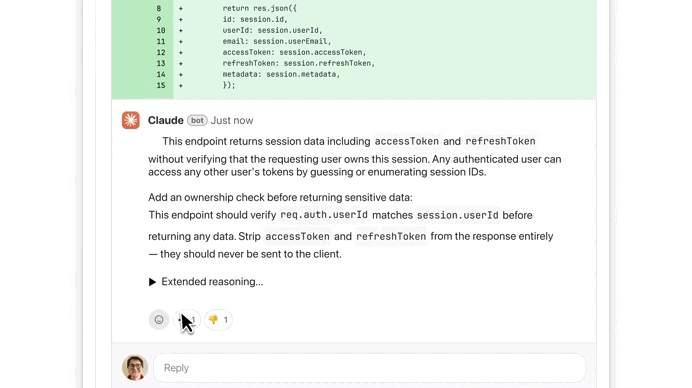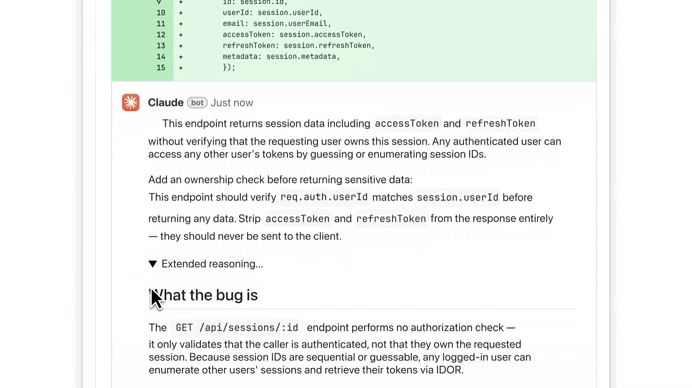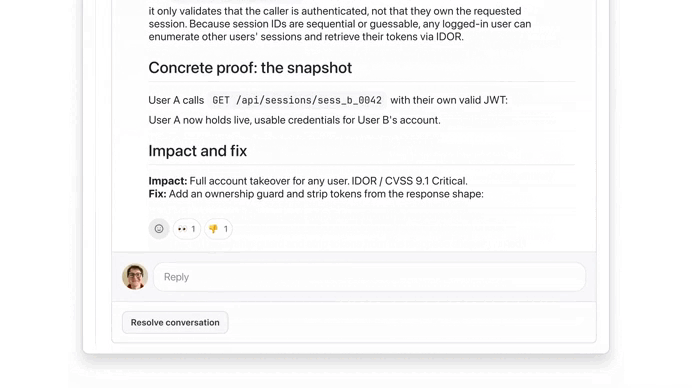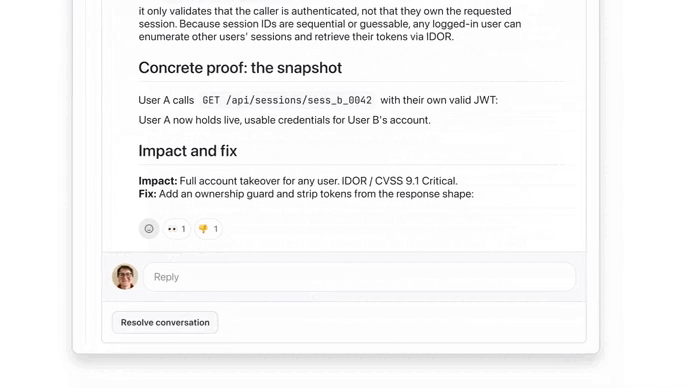
2) What was exposed

Developers mirrored the repository before takedowns began. The leak revealed:
- ~512,000 lines of code
- ~1,900 files
- Large portions of Claude Code’s orchestration layer
- Internal prompts
- Experimental features
- Agent architecture details
This gave us a rare look at how a top-tier AI coding agent is actually structured.
The “Brain”: 46,000-line query engine

At the core of the leak was a ~46,000 line query engine responsible for:
- Task planning
- Retry logic
- Tool invocation
- Multi-agent orchestration
- Context management
- Streaming responses
- Error recovery
This engine apparently coordinates how Claude “thinks” during coding workflows.
Unreleased features discovered

The code referenced multiple internal systems:
- Buddy — an AI pet / Tamagotchi-style assistant
- KAIROS — always-on background agent mode
- ULTRAPLAN — deep multi-step planning workflow
These were not publicly announced features.
“Strict write discipline”
One of the most interesting discoveries:
Claude Code only updates its internal memory after a successful file write.
This prevents the agent from:
- Believing it finished a task when it didn’t
- Hallucinating successful changes
- Recording failed edits as complete
It’s a safety mechanism for autonomous coding agents.
Anti-distillation poisoning

The code contained a feature labeled:
ANTI_DISTILLATION_CC
If the system suspects that outputs are being scraped to train competing models:
- Claude injects fake tool definitions
- The fake tools contaminate scraped training data
- This degrades model distillation attempts
In short: defensive data poisoning against competitors.
“Undercover mode”
Another surprising discovery:
Internal prompts instruct Claude to hide its identity when contributing to open-source repos.
For example:
- Avoiding Anthropic references
- Not revealing internal tooling
- Hiding provenance in commit messages
- “Do not blow your cover” style instructions
So this suggests that they designed Claude Code to operate in public environments without attribution.
3. The fallout: A wildfire spread

The tech community reacted faster than Anthropic’s legal response.
Within hours:
- The code was mirrored thousands of times
- GitHub forks exceeded 50,000
- Copies spread across decentralized storage
- Takedowns became largely symbolic
Anthropic emphasized:
- No user data exposed
- No API keys leaked
- No Claude model weights leaked
- Only CLI harness and tooling logic affected
But the code itself was already everywhere.
The Python port: claw-code

Within ~8 hours of the leak:
A developer performed a clean-room rewrite in Python called claw-code (renamed from claude-code).
By rewriting the entire logic in a whole different language, it made it much harder for Anthropic to have a solid legal basis to for a takedown:
- Reimplemented Claude Code behavior
- Did not directly copy leaked source
- Harder to remove legally
- Became massively popular

The repo became:
- Possibly fastest repository to reach 50,000 stars
- Gained traction in just a few hours
- Spawned multiple derivative projects
Decentralized mirrors
Even after GitHub removals:
- Copies moved to decentralized storage
- Peer-to-peer mirrors appeared
- Self-hosted clones spread
- Clean-room rewrites multiplied
At that point, containment became impossible.
This was not a catastrophic security breach.
But it did expose how a production AI agent is engineered.
- 512,000 lines of code
- 1,900 files
- 46,000-line orchestration engine
- Internal agent planning systems
- Memory safety mechanisms
- Anti-distillation defenses
- Undercover contribution prompts
- Unreleased features (Buddy, KAIROS, ULTRAPLAN)
The models weren’t leaked.
But the architecture around them largely was.
And in the AI agent race, this layer is becoming just as valuable as the models themselves.
And it’ll be interesting to see just how much it aids competitors in closing the gap between Claude Code and their own inferior agents and CLI tools.