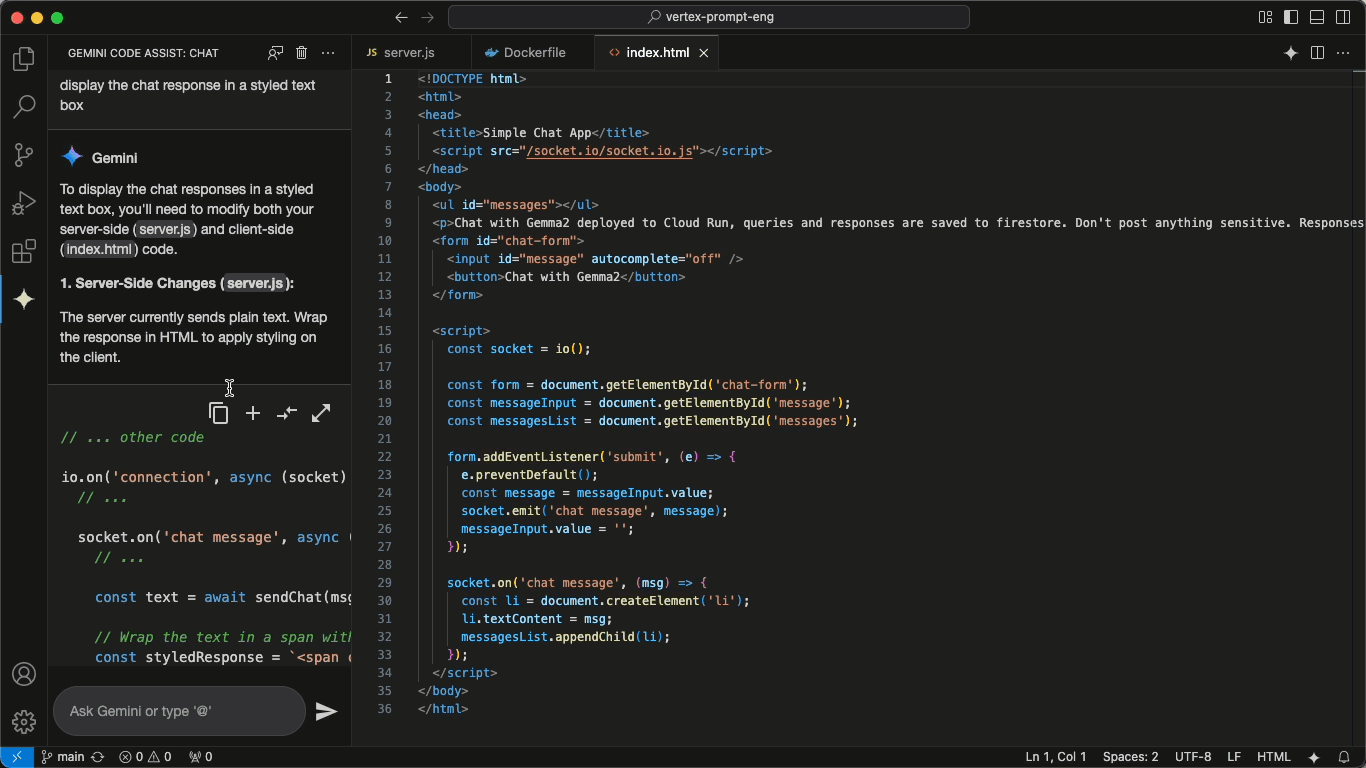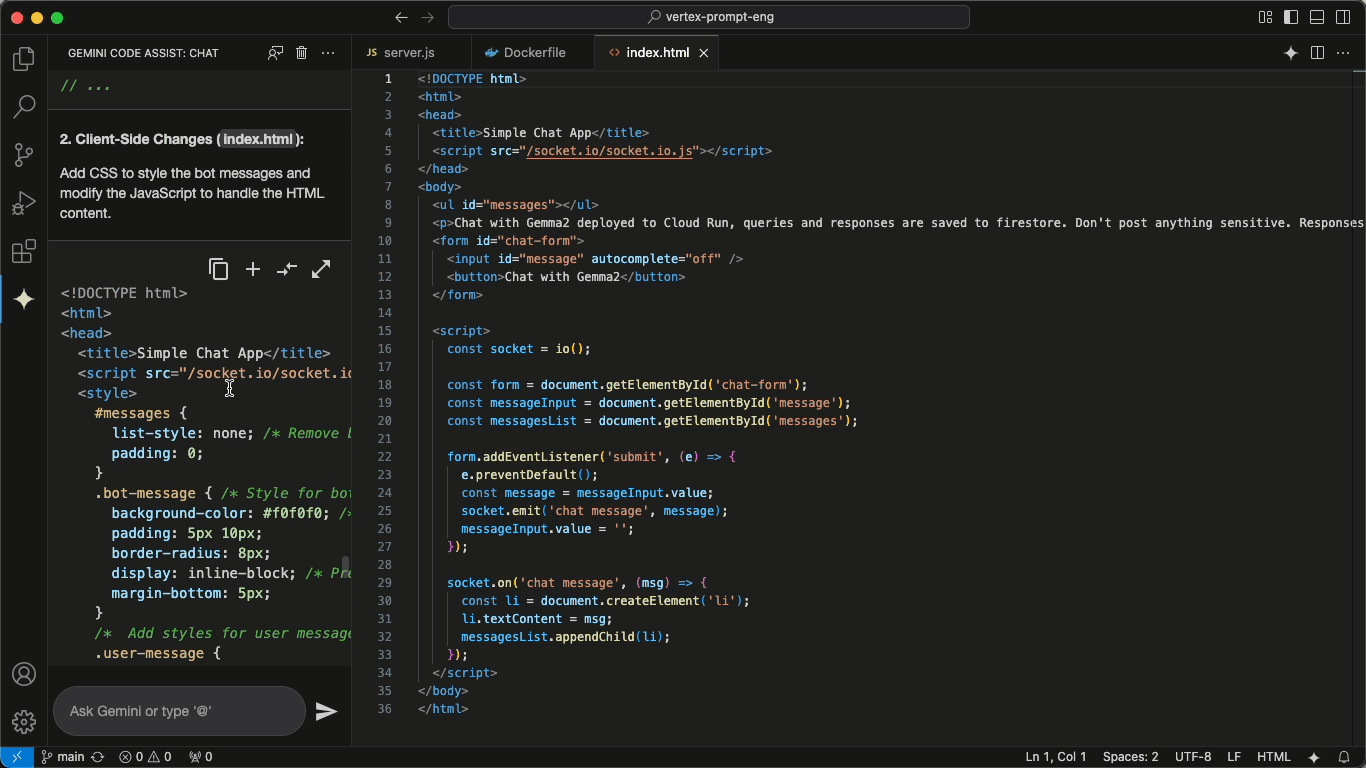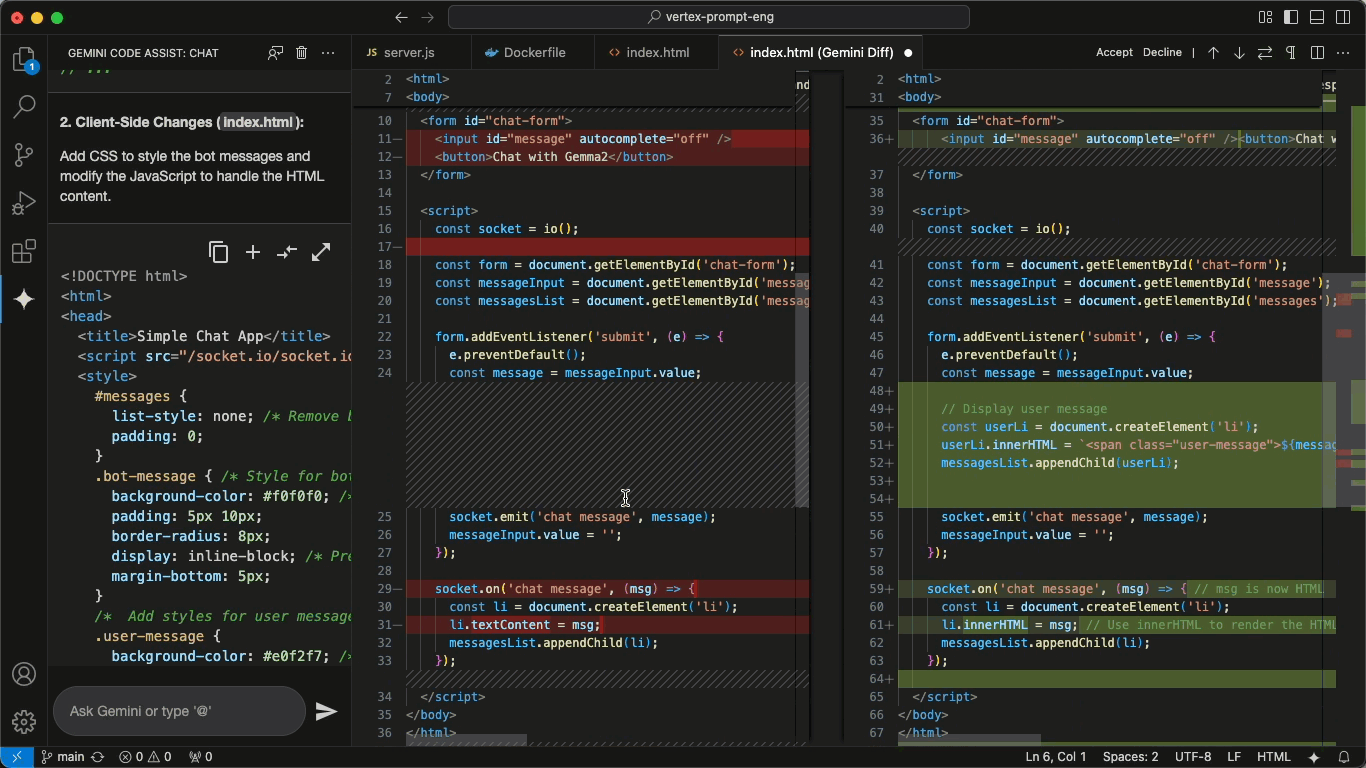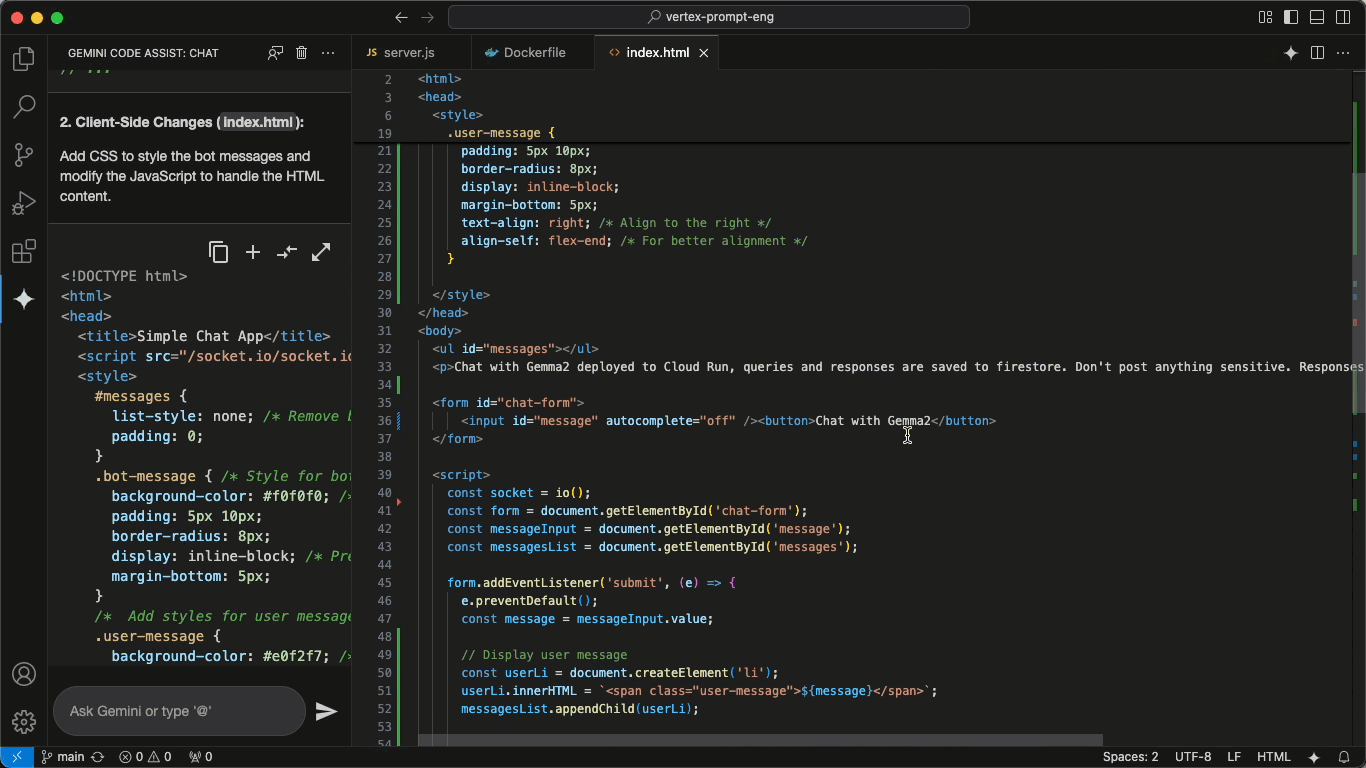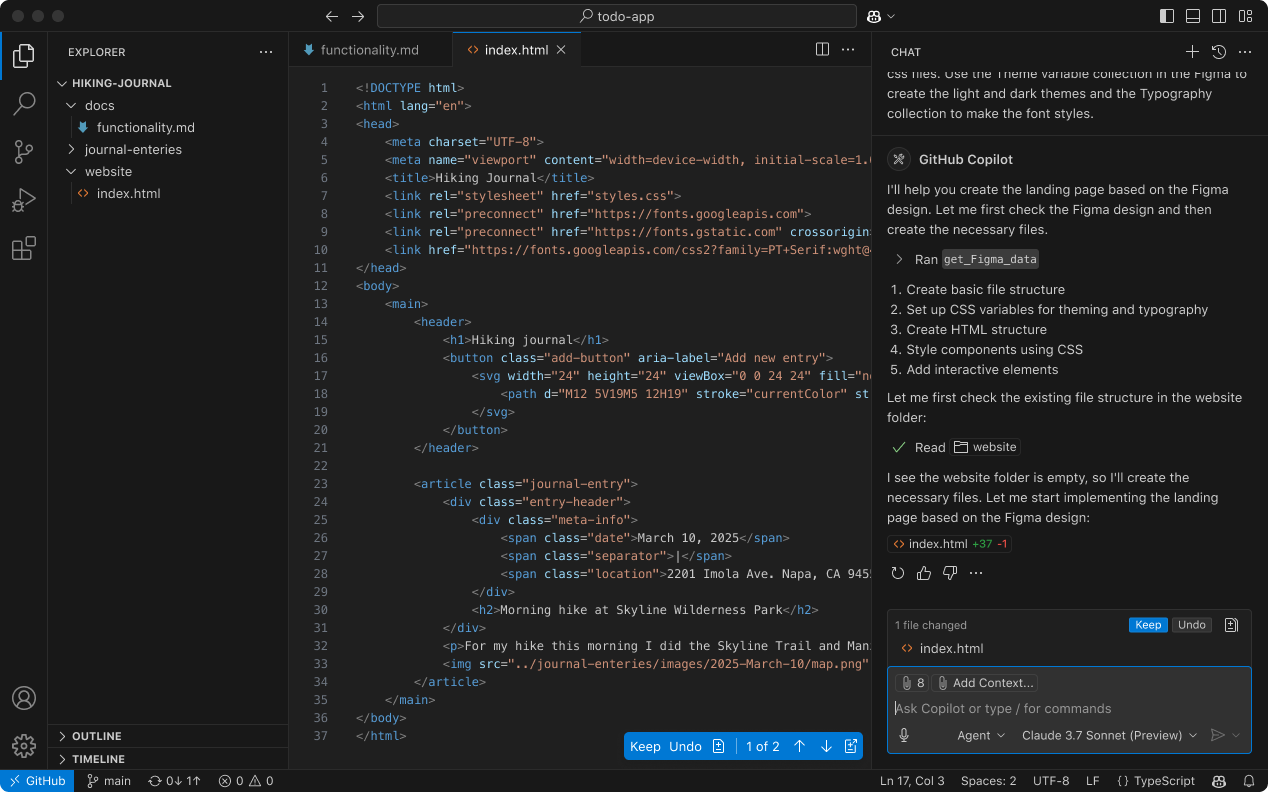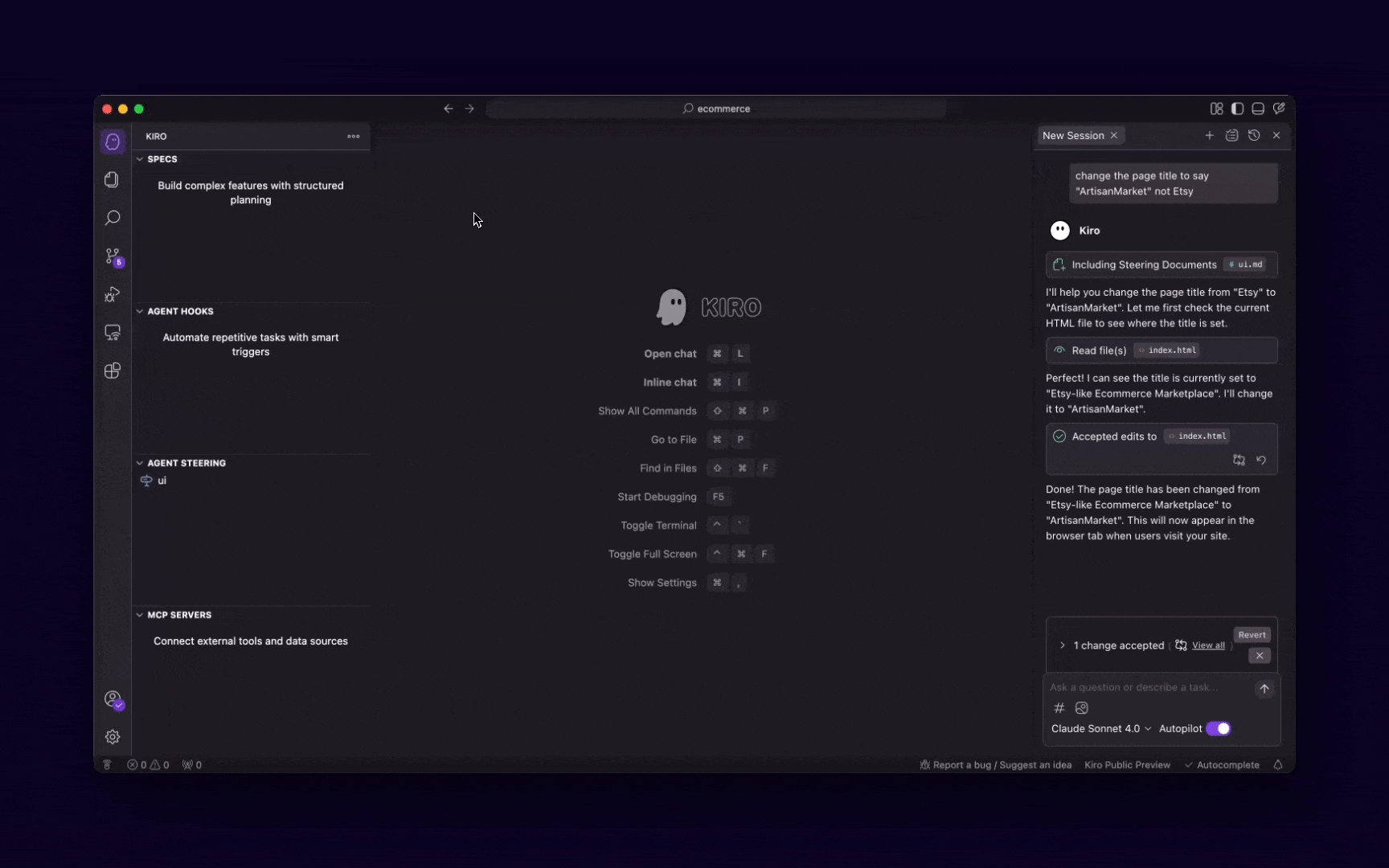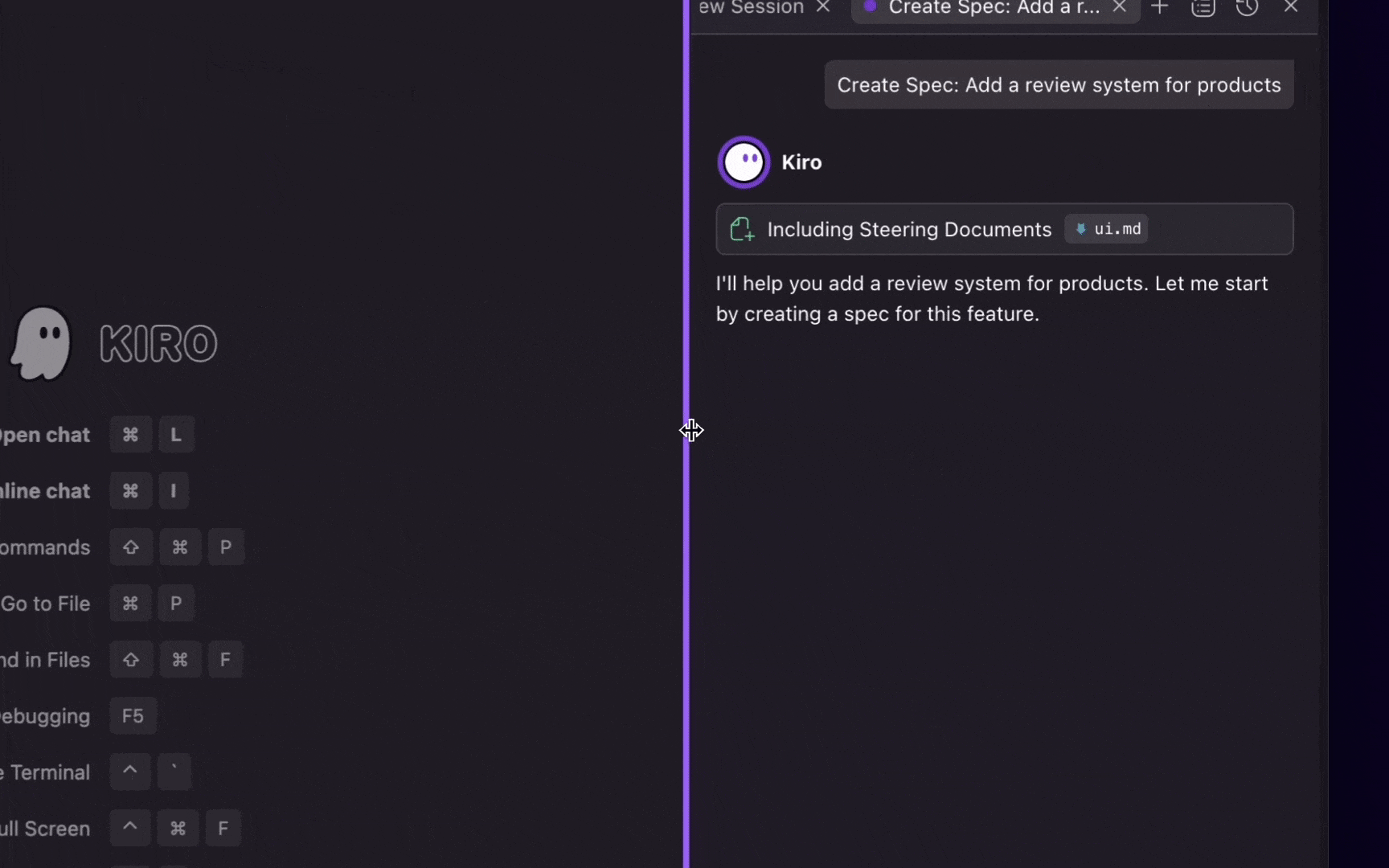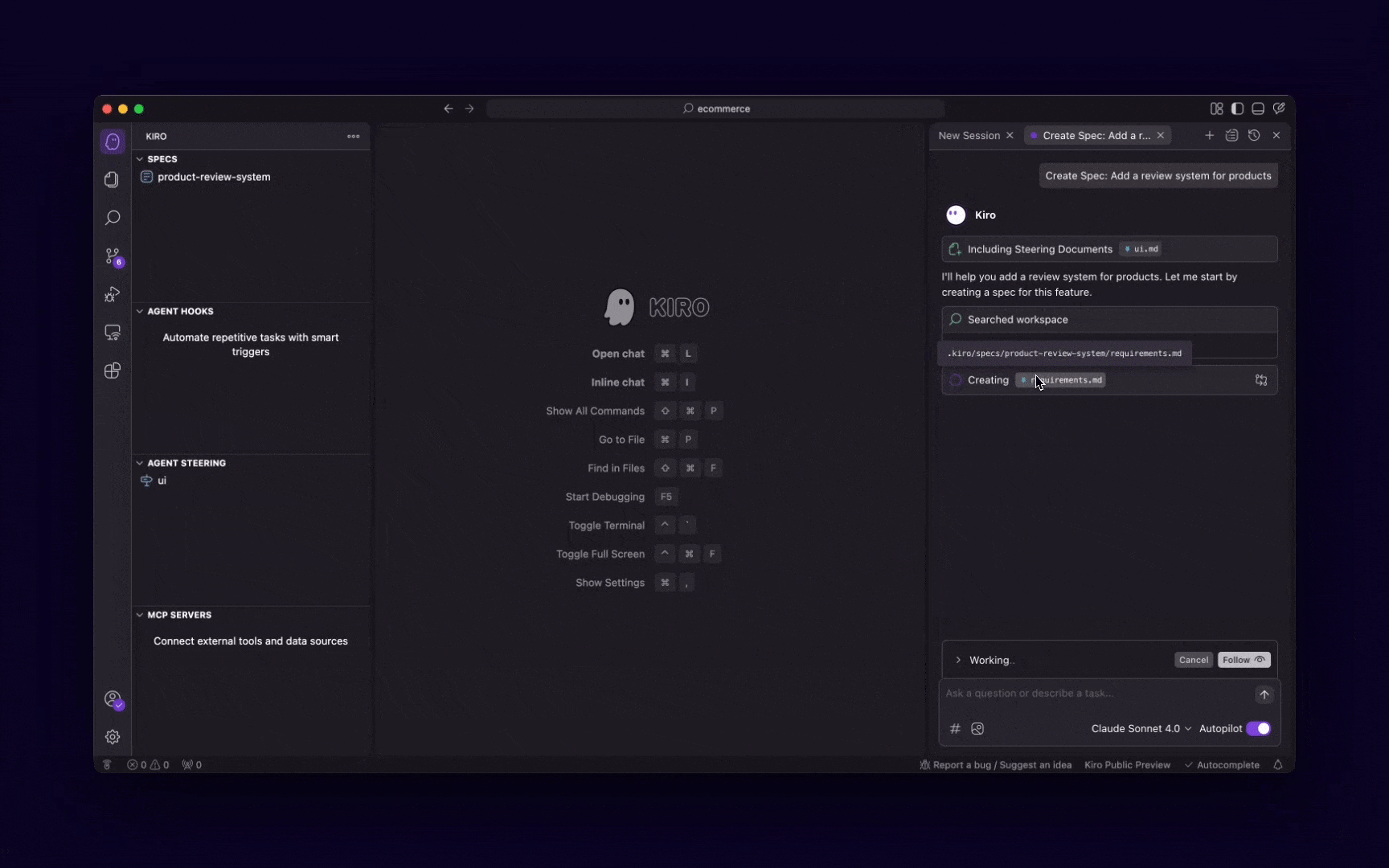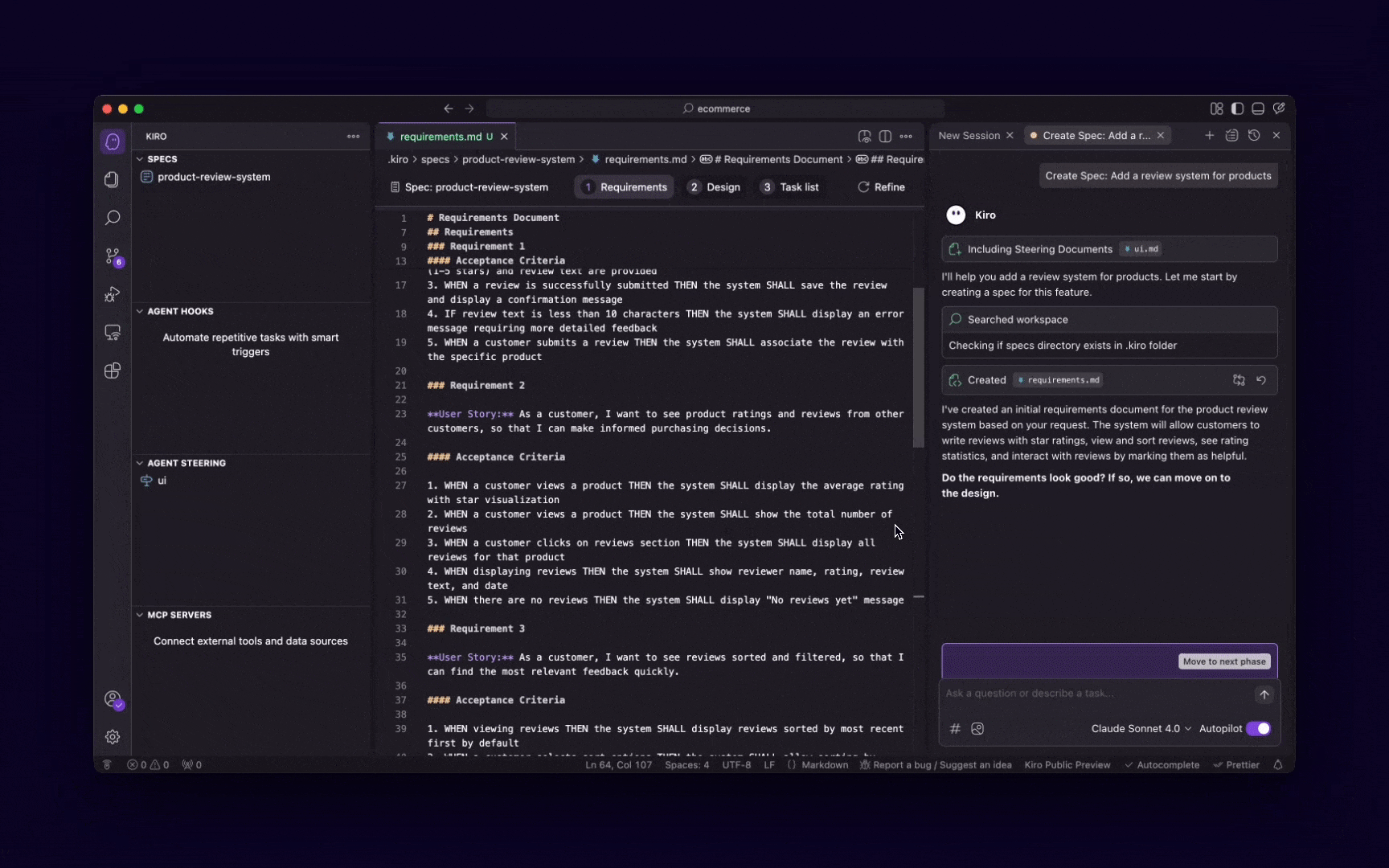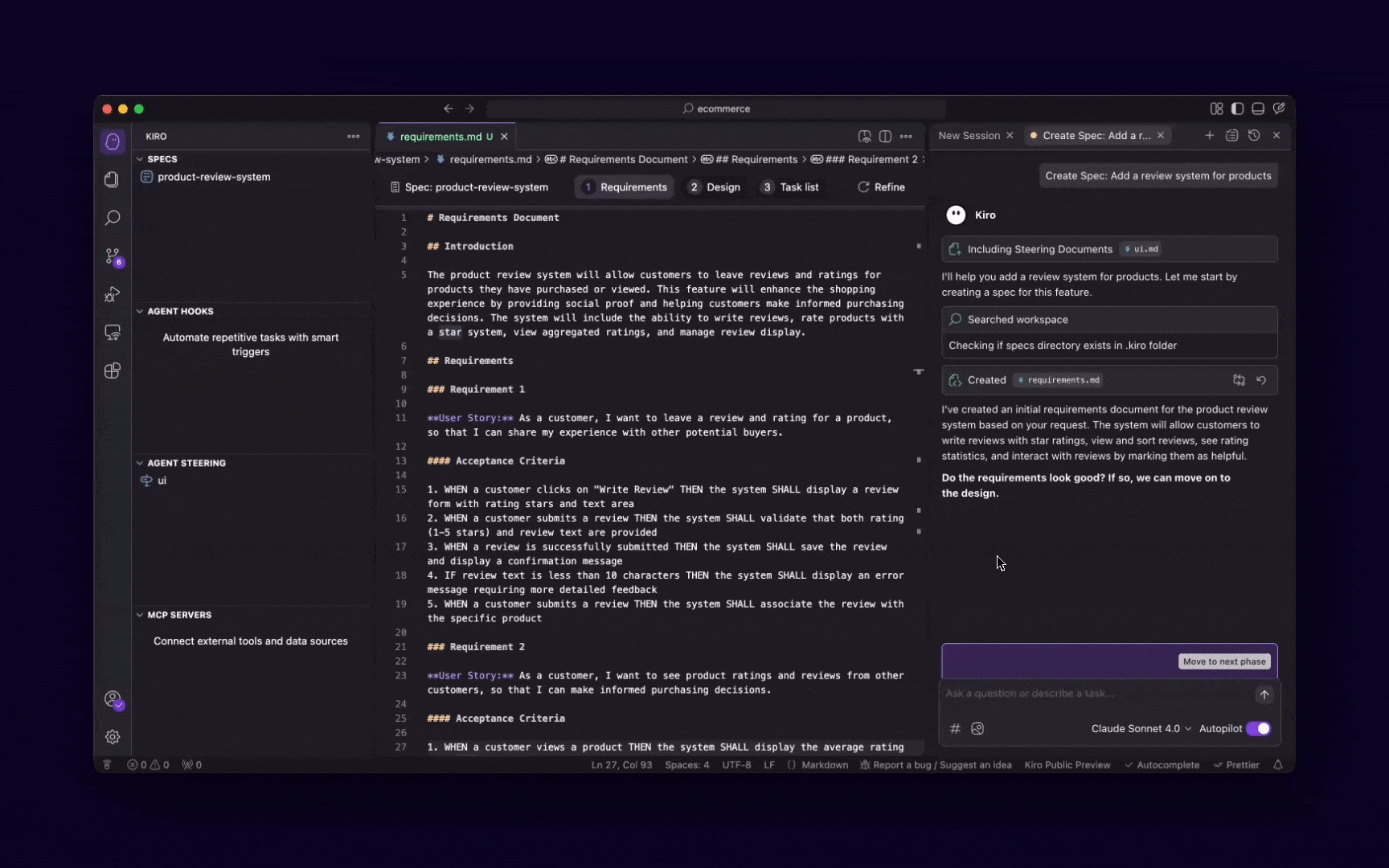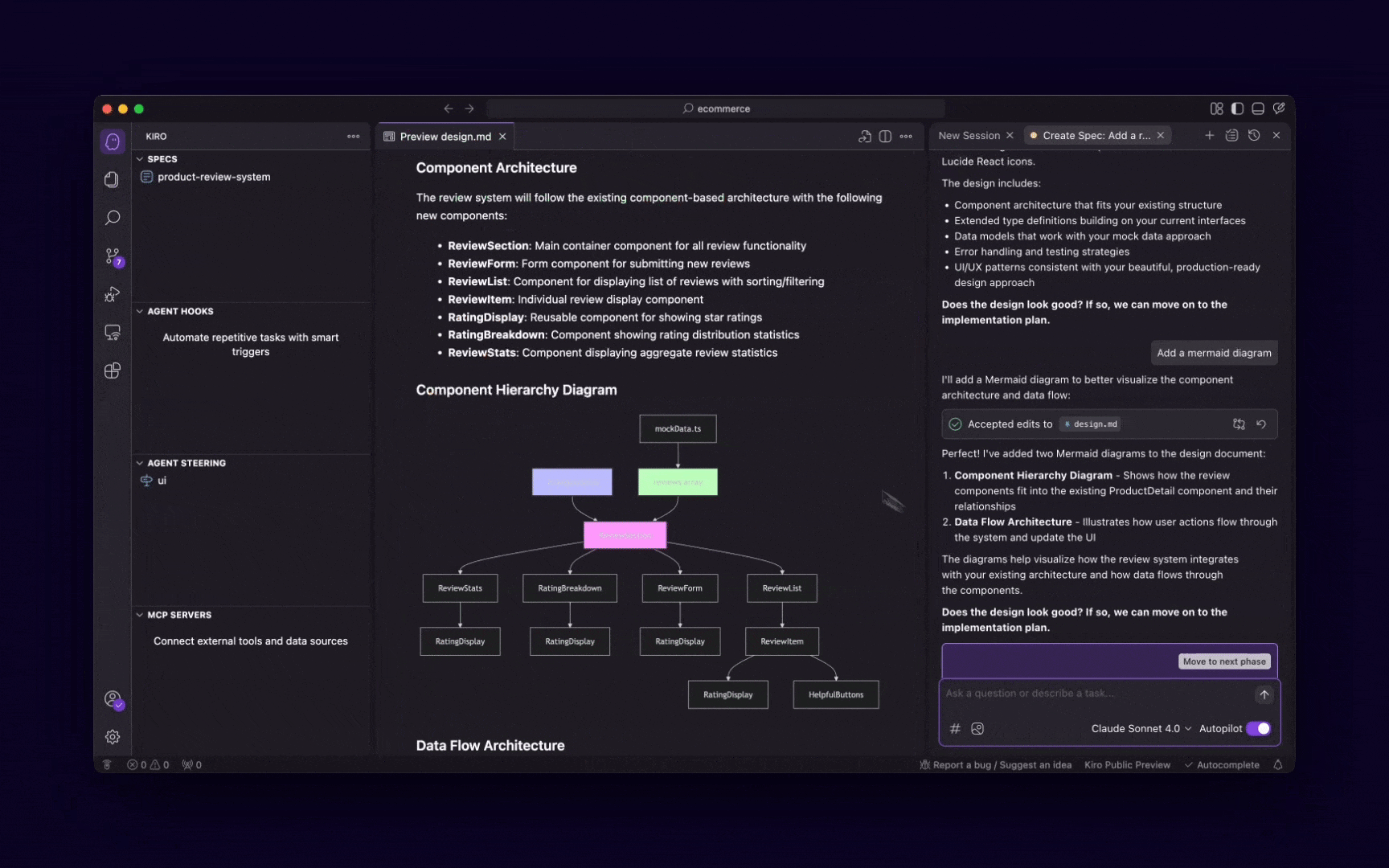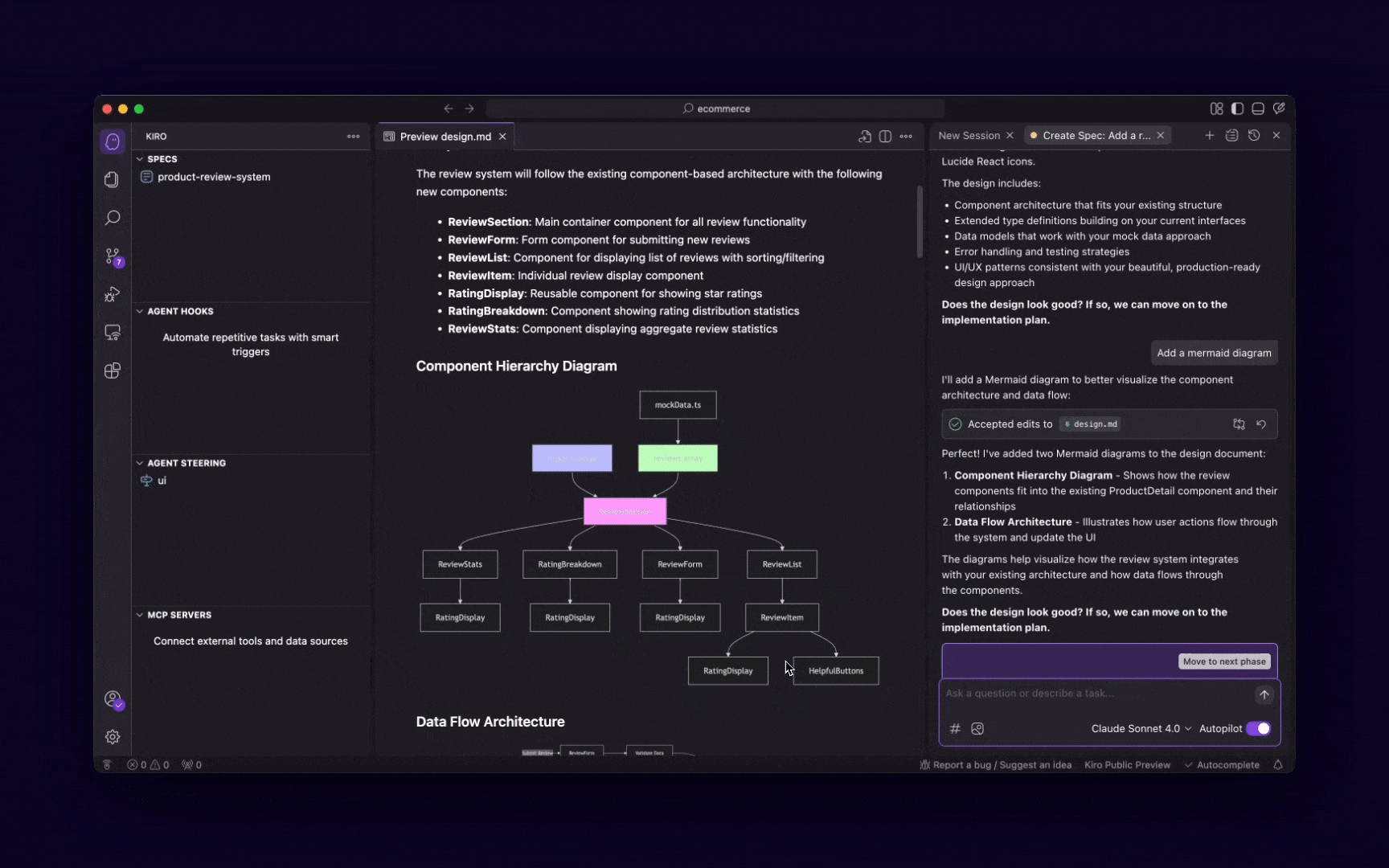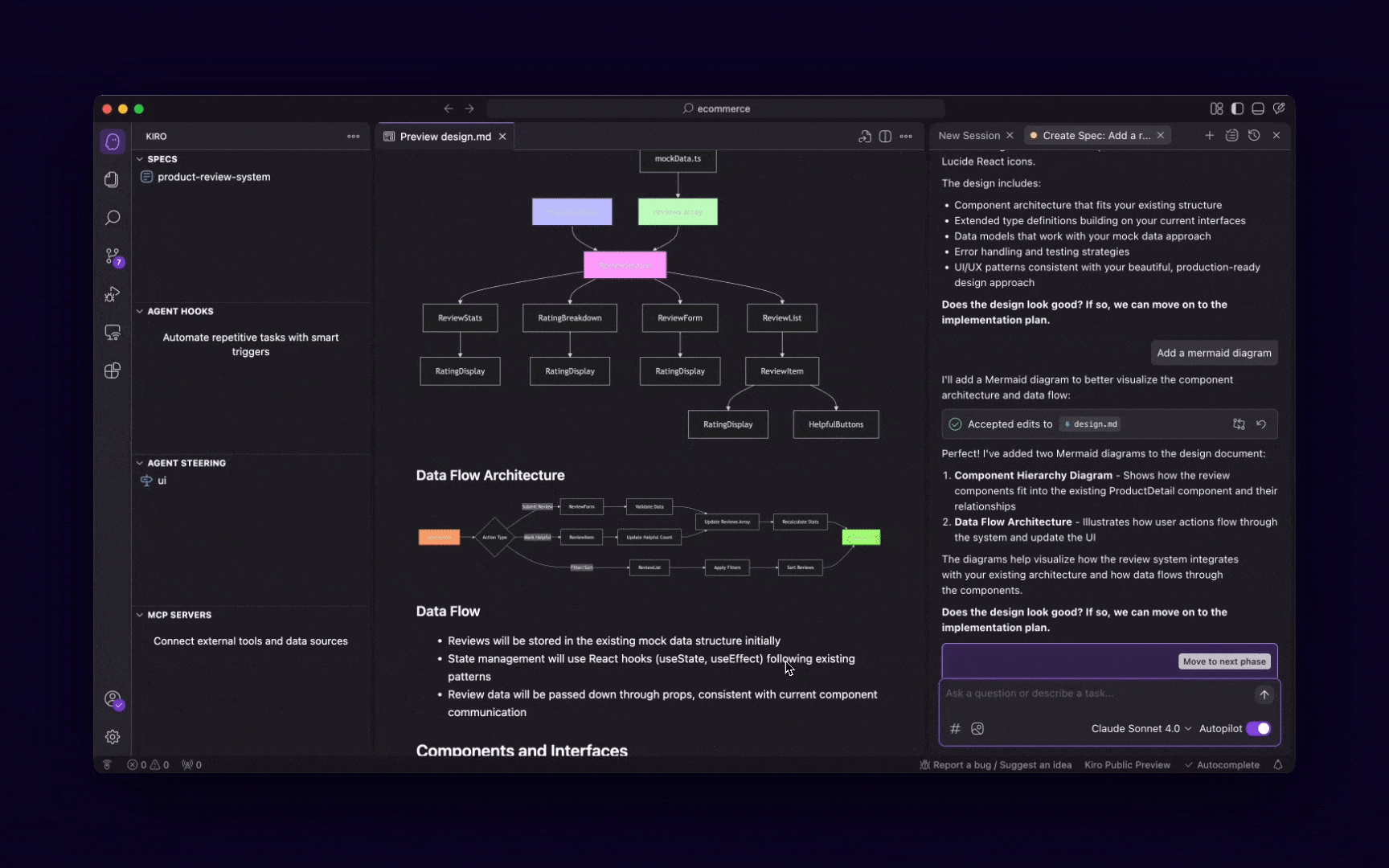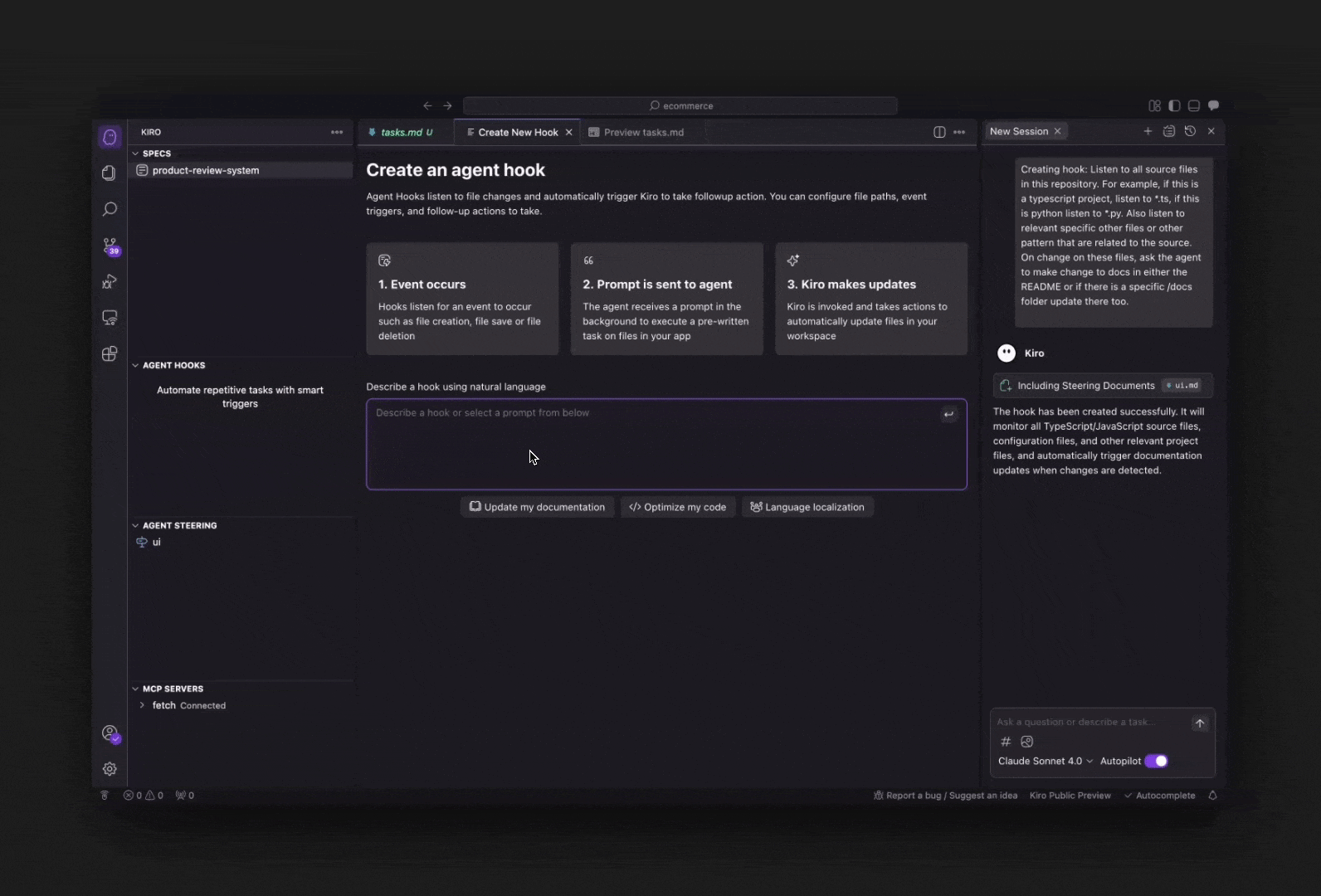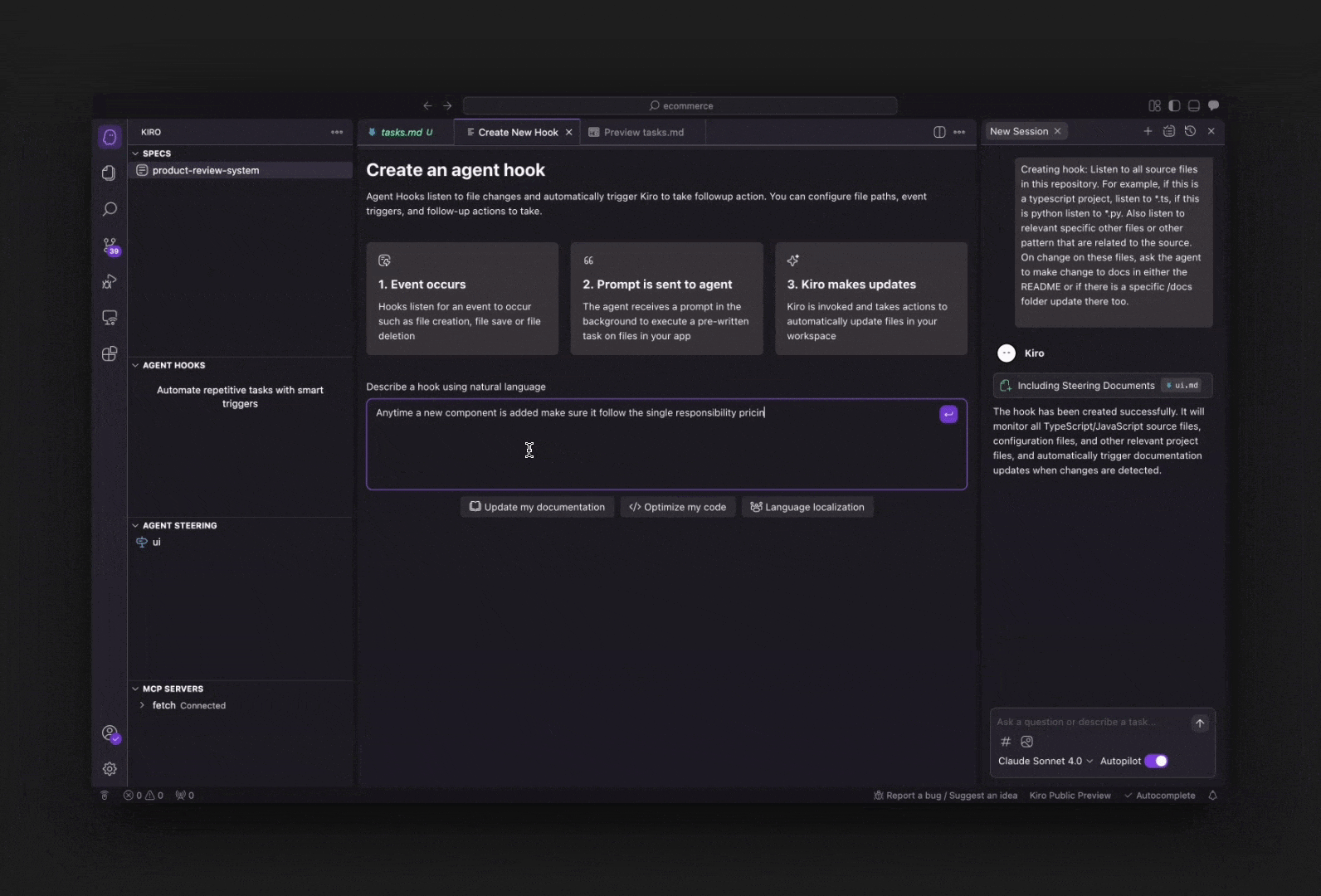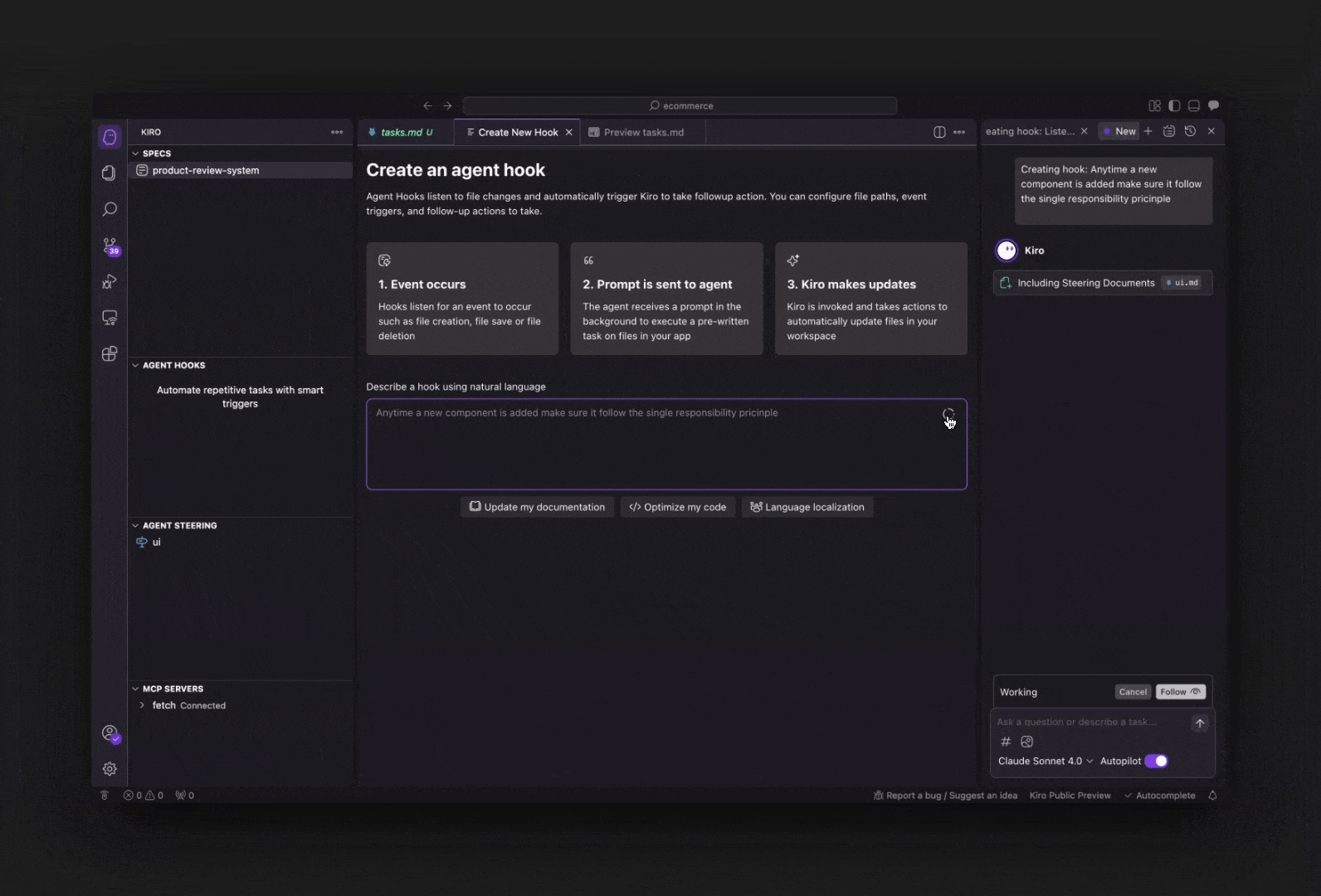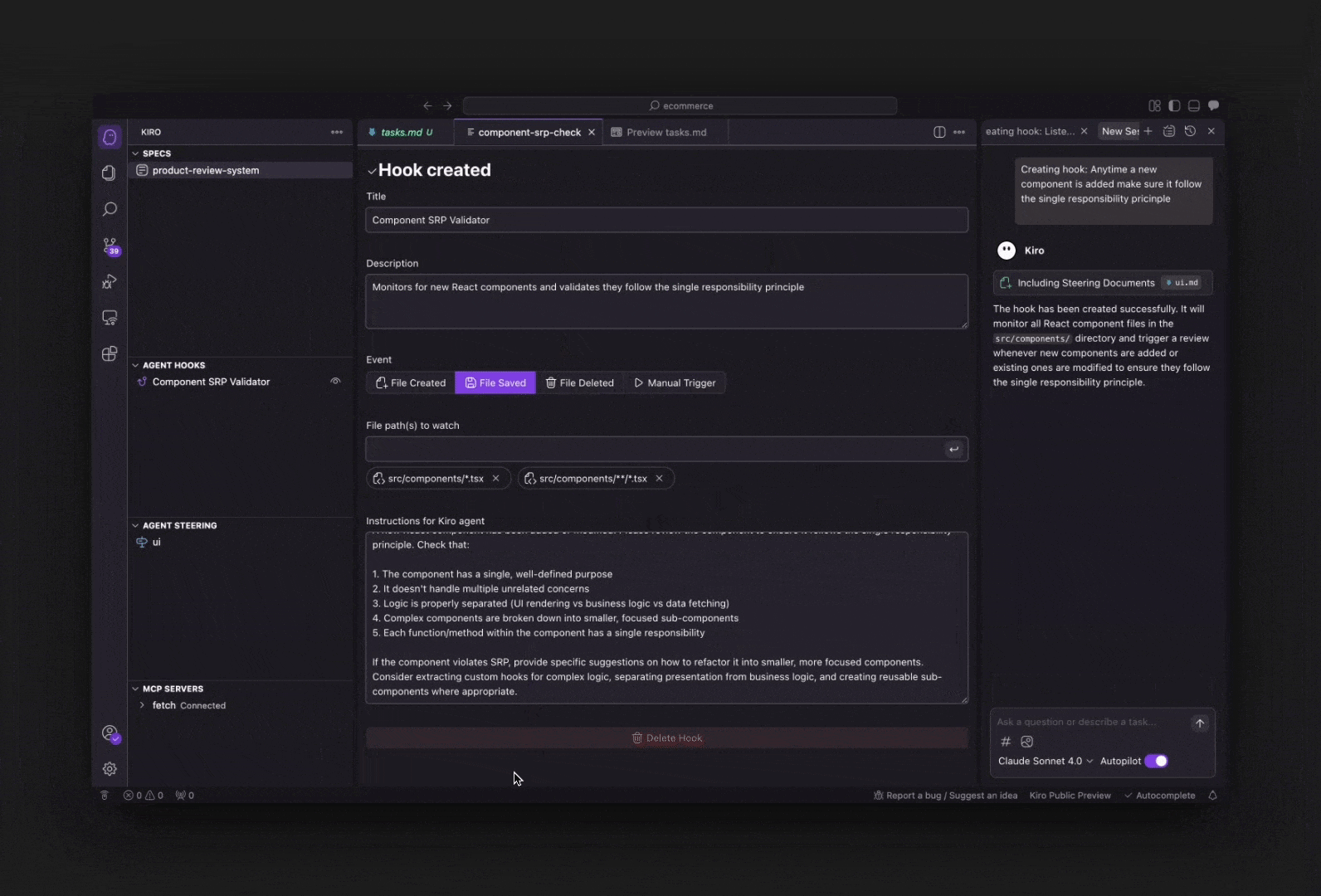
These 5 MCP servers reduce AI code errors by 99% (perfect context)
AI coding assistants are amazing and powerful—until they start lying.
Like it just gets really frustrating when they hallucinate APIs or forget your project structure and break more than they fix.
And why does this happen?
Context.
They just don’t have enough context.
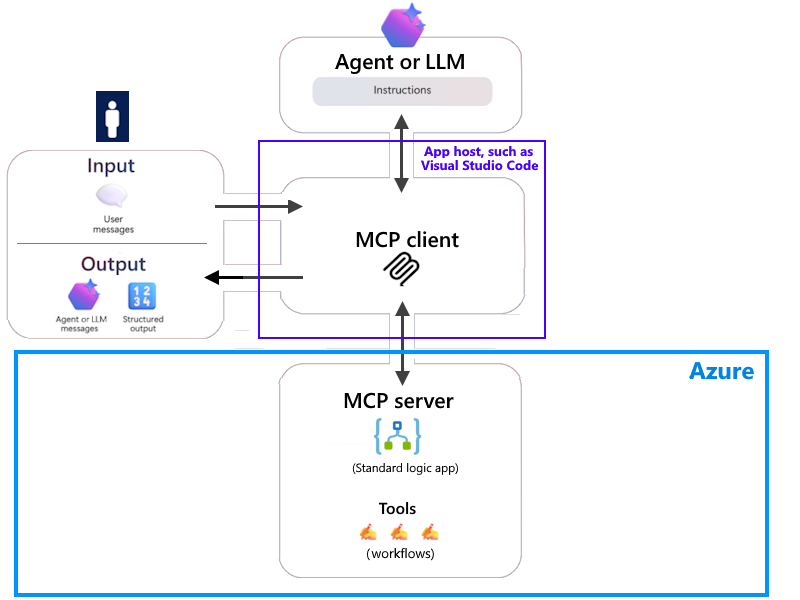
Context is everything for AI assistants. That’s why MCP is so important.
These MCP servers fix that. They ground your AI in the truth of your codebase—your files, libraries, memory, and decisions—so it stops guessing and starts delivering.
These five will change everything.
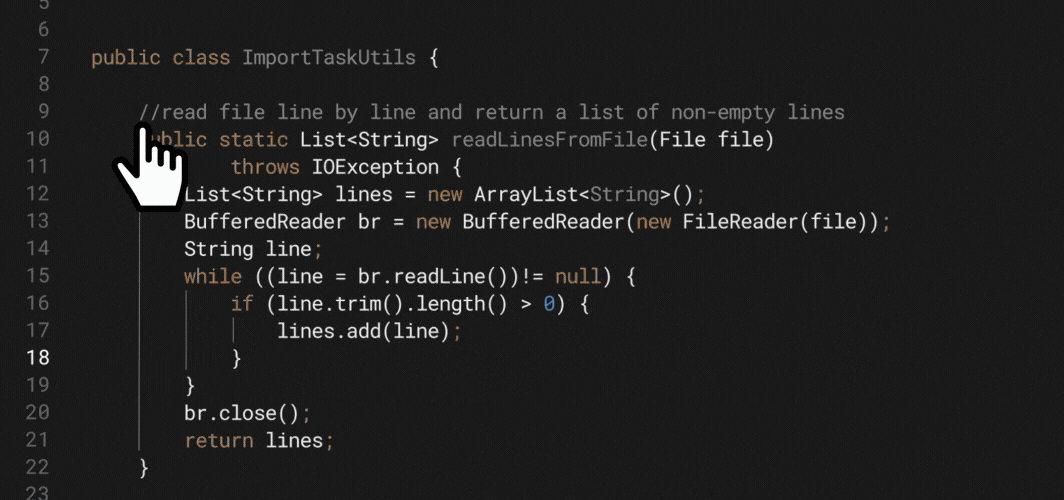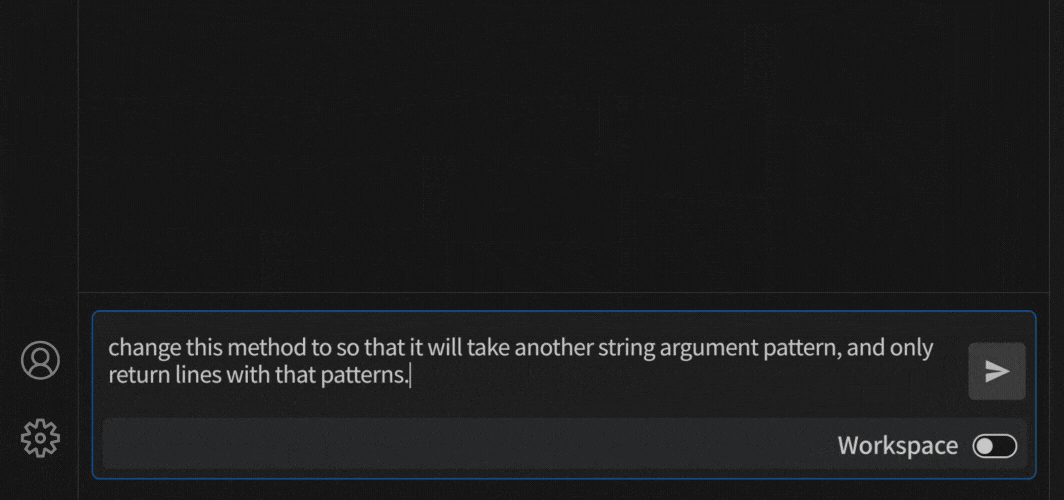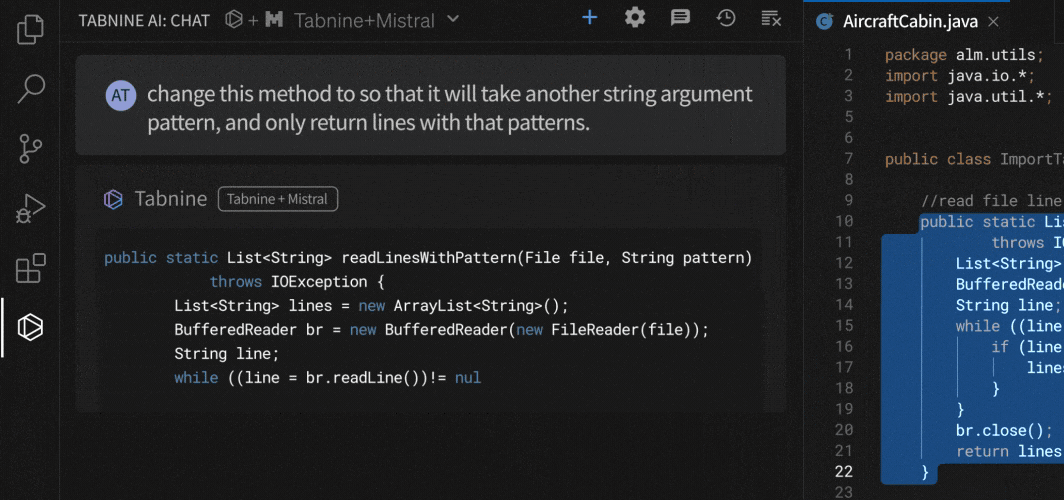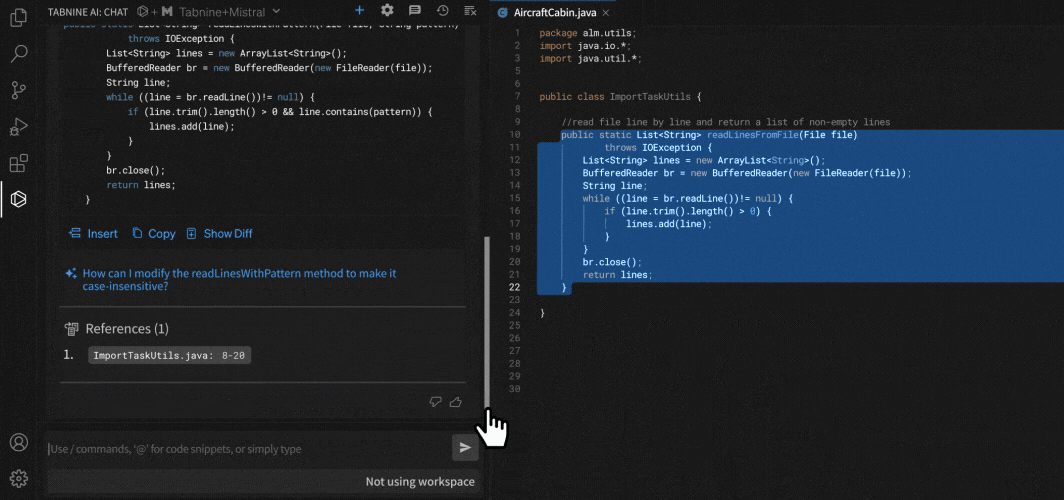
Context7 MCP Server
Context7 revolutionizes how AI models interact with library documentation—eliminating outdated references, hallucinated APIs, and unnecessary guesswork.
It sources up-to-date, version-specific docs and examples directly from upstream repositories — to ensure every answer reflects the exact environment you’re coding in.
Whether you’re building with React, managing rapidly evolving dependencies, or onboarding a new library, Context7 keeps your AI grounded in reality—not legacy docs.
It seamlessly integrates with tools like Cursor, VS Code, Claude, and Windsurf, and supports both manual and automatic invocation. With just a line in your prompt or an MCP rule, Context7 starts delivering live documentation, targeted to your exact project context.
Key features
- On-the-fly documentation: Fetches exact docs and usage examples based on your installed library versions—no hallucinated syntax.
- Seamless invocation: Auto-invokes via MCP client config or simple prompt cues like “use context7”.
- Live from source: Pulls real-time content straight from upstream repositories and published docs.
- Customizable resolution: Offers tools like
resolve-library-idandget-library-docsto fine-tune lookups. - Wide compatibility: Works out-of-the-box with most major MCP clients across dozens of programming languages.
Errors it prevents
- Calling deprecated or removed APIs
- Using mismatched or outdated function signatures
- Writing syntax that no longer applies to your version
- Missing new required parameters or arguments
- Failing to import updated module paths or packages
Powerful use cases
- Projects built on fast-evolving frameworks like React, Angular, Next.js, etc.
- Onboarding to unfamiliar libraries without constant tab switching
- Working on teams where multiple versions of a library may be in use
- Auditing legacy codebases for outdated API usage
- Auto-generating code or tests with correct syntax and parameters for specific versions
Get Context7 MCP Server: LINK
Memory Bank MCP Server
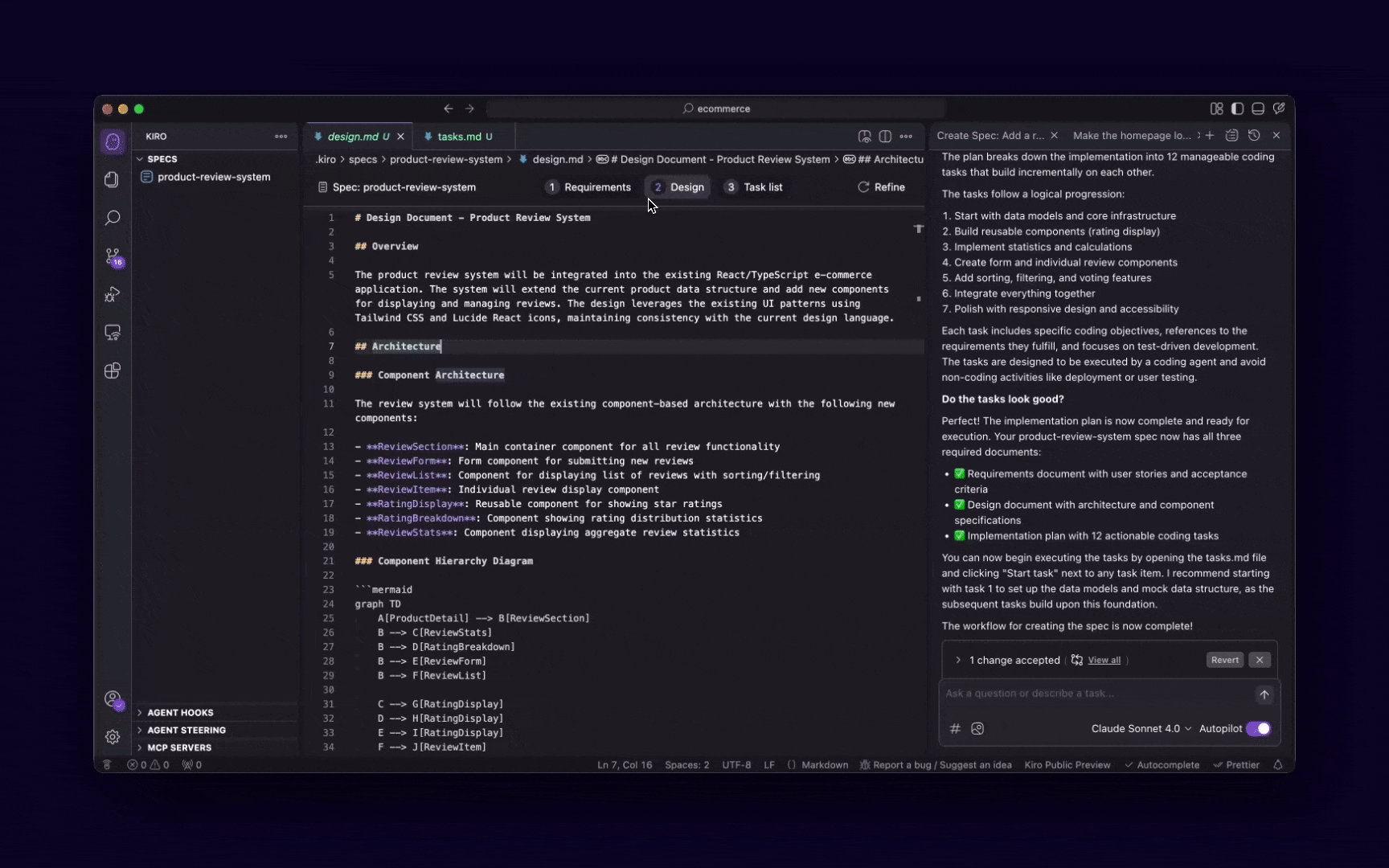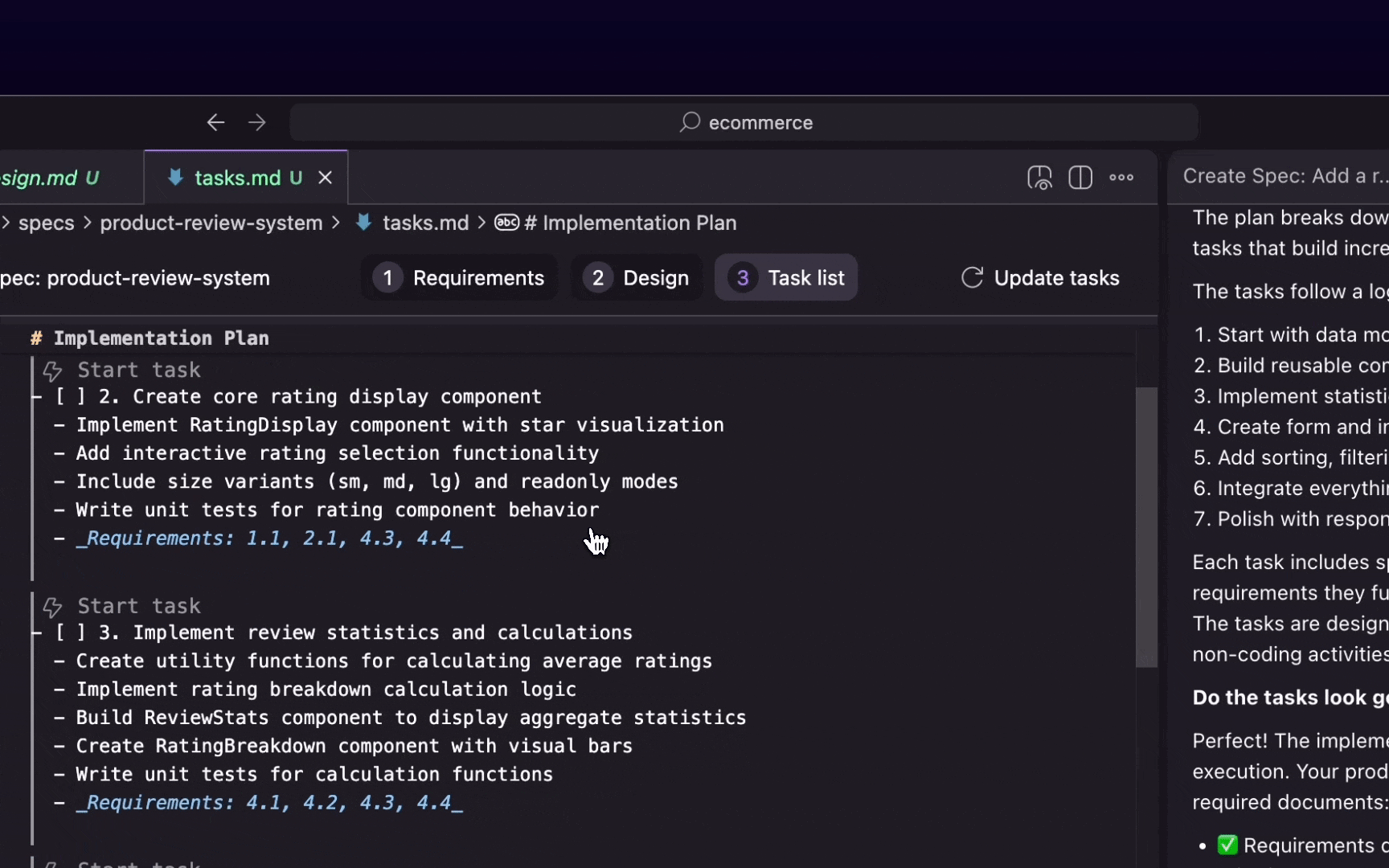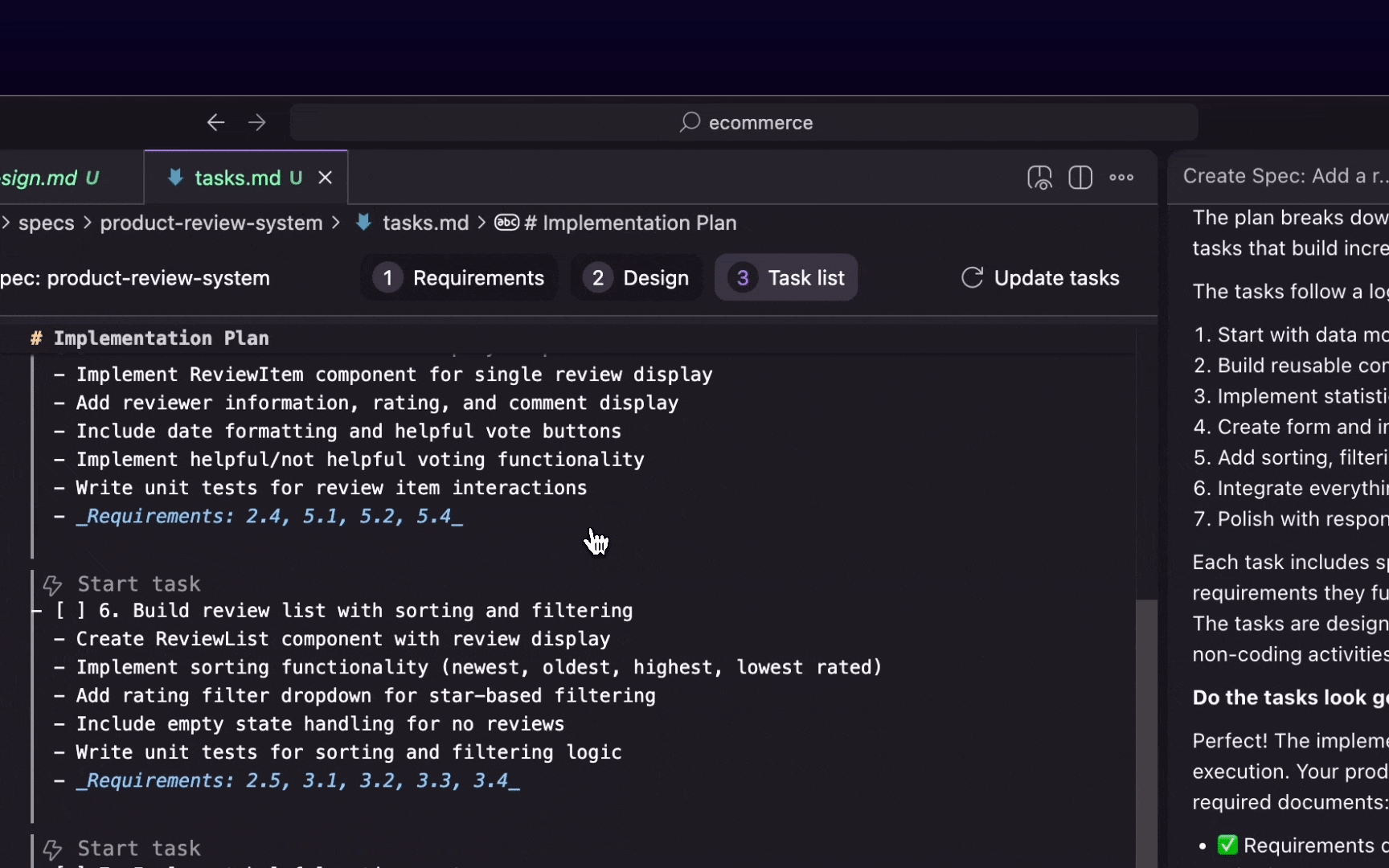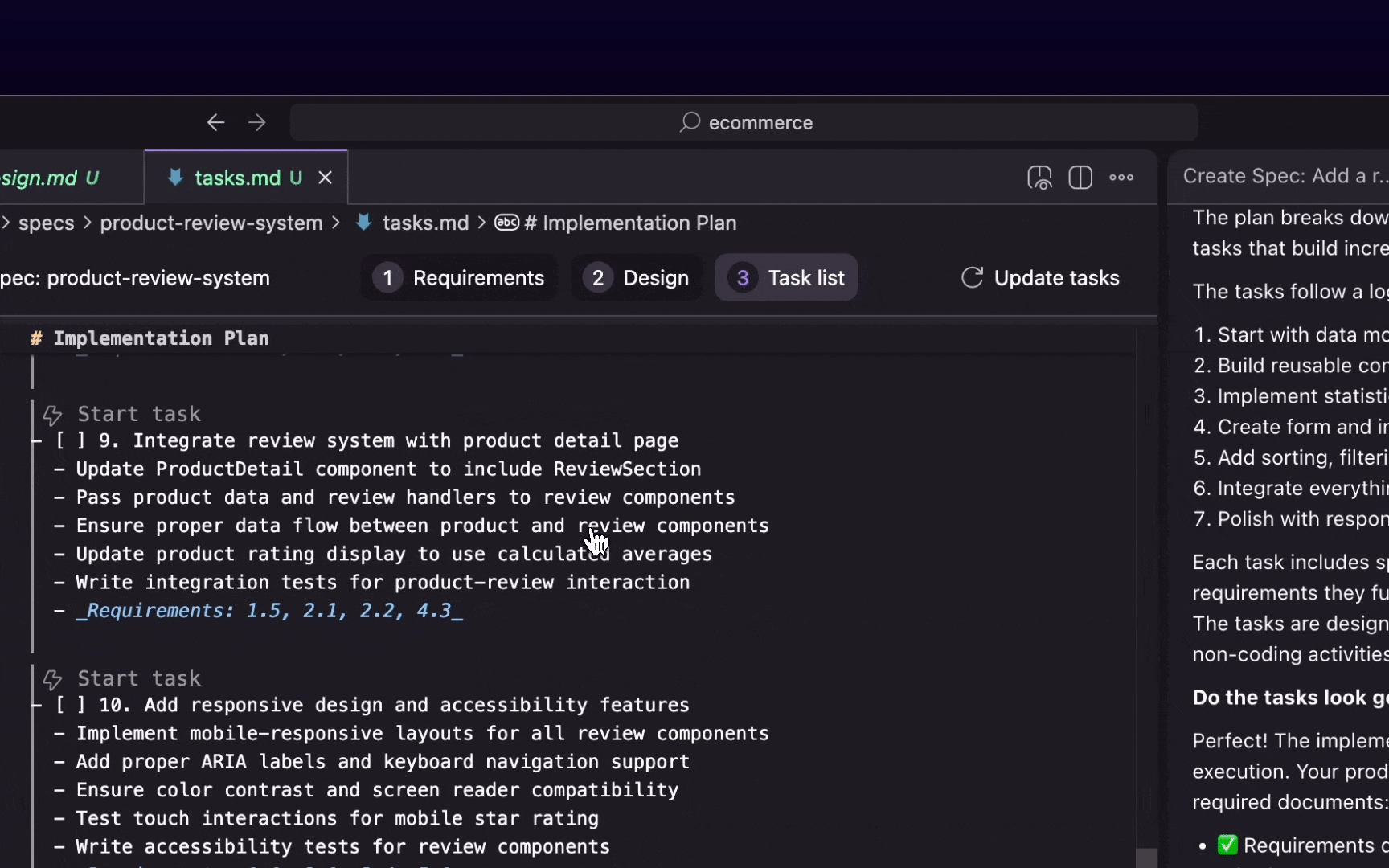
The Memory Bank MCP server gives your AI assistant persistent memory across coding sessions and projects.
Instead of repeating the same explanations, code patterns, or architectural decisions, your AI retains context from past work—saving time and improving coherence. It’s built to work across multiple projects with strict isolation, type safety, and remote access, making it ideal for both solo and collaborative development.
Key features
- Centralized memory service for multiple projects
- Persistent storage across sessions and application restarts
- Secure path traversal prevention and structure enforcement
- Remote access via MCP clients like Claude, Cursor, and more
- Type-safe read, write, and update operations
- Project-specific memory isolation
Errors it prevents
- Duplicate or redundant function creation
- Inconsistent naming and architectural patterns
- Repeated explanations of project structure or goals
- Lost decisions, assumptions, and design constraints between sessions
- Memory loss when restarting the AI or development environment
Powerful use cases
- Long-term development of large or complex codebases
- Teams working together on shared projects needing consistent context
- Developers aiming to preserve and reuse design rationale across sessions
- Projects with strict architecture or coding standards
- Solo developers who want continuity and reduced friction when resuming work
Get Memory Bank MCP Server: LINK
Sequential Thinking MCP Server
Definitely one of the most important MCP servers out there anywhere.
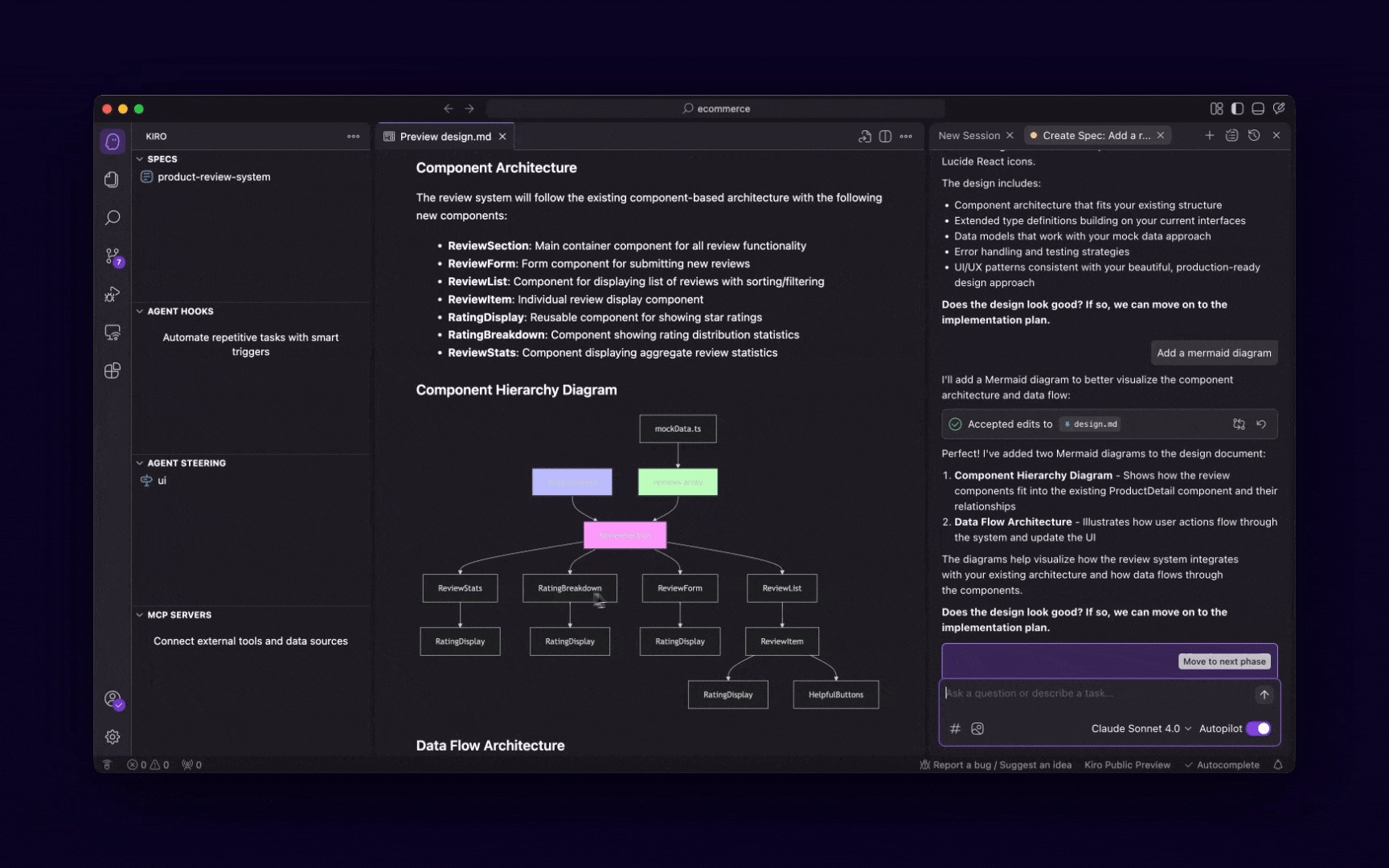
It’s designed to guide AI models through complex problem-solving processes — it enables structured and stepwise reasoning that evolves as new insights emerge.
Instead of jumping to conclusions or producing linear output, this server helps models think in layers—making it ideal for open-ended planning, design, or analysis where the path forward isn’t immediately obvious.
Key features
- Step-by-step thought sequences: Breaks down complex problems into numbered “thoughts,” enabling logical progression.
- Reflective thinking and branching: Allows the model to revise earlier steps, fork into alternative reasoning paths, or return to prior stages.
- Dynamic scope control: Adjusts the total number of reasoning steps as the model gains more understanding.
- Clear structure and traceability: Maintains a full record of the reasoning chain, including revisions, branches, and summaries.
- Hypothesis testing: Facilitates the generation, exploration, and validation of multiple potential solutions.
Errors it prevents
- Premature conclusions due to lack of iteration
- Hallucinated or shallow reasoning in complex tasks
- Linear, single-path thinking in areas requiring exploration
- Loss of context or rationale behind decisions in multi-step outputs
Powerful use cases
- Planning and project breakdowns
- Software architecture and design decisions
- Analyzing ambiguous or evolving problems
- Creative brainstorming and research direction setting
- Any situation where the model needs to explore multiple options or reflect on its own logic
Once you install it, it becomes a powerful extension of your model’s cognitive abilities—giving you not just answers, but the thinking behind them.
Get Sequential Thinking MCP Server: LINK
Filesystem MCP Server
The Filesystem MCP server provides your AI with direct, accurate access to your local project’s structure and contents.
Instead of relying on guesses or hallucinated paths, your agent can read, write, and navigate files with precision—just like a developer would. This makes code generation, refactoring, and debugging dramatically more reliable.
No more broken imports, duplicate files, or mislocated code. With the Filesystem MCP your AI understands your actual workspace before making suggestions.
Key features
- Read and write files programmatically
- Create, list, and delete directories with precise control
- Move and rename files or directories safely
- Search files using pattern-matching queries
- Retrieve file metadata and directory trees
- Restrict all file access to pre-approved directories for security
Ideal scenarios
- Managing project files during active development
- Refactoring code across multiple directories
- Searching for specific patterns or code smells at scale
- Debugging with accurate file metadata
- Maintaining structural consistency across large codebases
Get FileSystem MCP: LINK
GitMCP
AI assistants can hallucinate APIs, suggest outdated patterns, and sometimes overwrite code that was just written.
GitMCP solves this by making your AI assistant fully git-aware—enabling it to understand your repository’s history, branches, files, and contributor context in real time.
Whether you’re working solo or in a team, GitMCP acts as a live context bridge between your local development environment and your AI tools. Instead of generic guesses, your assistant makes informed suggestions based on the actual state of your repo.
GitMCP is available as a free, open-source MCP server, accessible via gitmcp.io/{owner}/{repo} or embedded directly into clients like Cursor, Claude Desktop, Windsurf, or any MCP-compatible tool. You can also self-host it for privacy or customization.
Key features
- Full repository indexing with real-time context
- Understands commit and branch history
- Smart suggestions based on existing code and structure
- Lightweight issue and contributor context integration
- Live access to documentation and source via GitHub or GitHub Pages
- No setup required for public repos—just add a URL and start coding
Errors it prevents
- Code conflicts with recent commits
- Suggestions that ignore your branching strategy
- Overwriting teammates’ changes during collaboration
- Breaking functionality due to missing context
- AI confusion from outdated or hallucinated repo structure
Ideal scenarios
- Collaborating in large teams with frequent commits
- Working on feature branches that need context-specific suggestions
- Reviewing and resolving code conflicts with full repo awareness
- Structuring AI-driven workflows around GitHub issues
- Performing large-scale refactors across multiple files and branches
Get GitMCP: LINK