
Woah this is huge.
China’s Z.ai just released their brand new GLM-5 model and it’s absolutely incredible. I hope Windsurf adds support for this ASAP…
This is not just a “coding” model. This is full-blown software engineering.
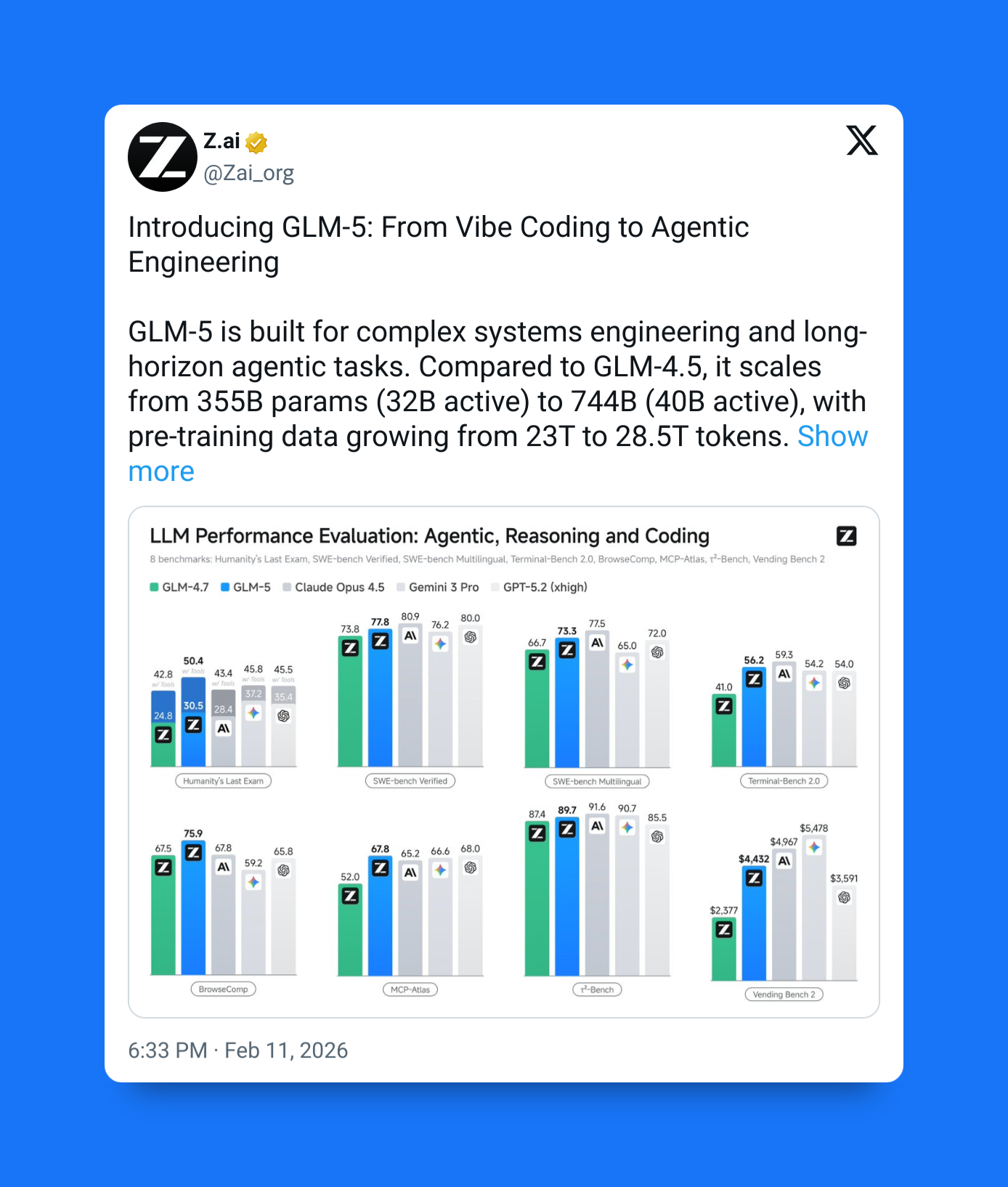
They designed it from the ground up to build highly complex systems and intricate dev workflows.
Record-low hallucinations — from 90% in the previous version… to 34% in GLM-5. Thanks to a groundbreaking approach to training the model.
Like for example if I ask the model a question it doesn’t know — it’s more likely to just tell me it doesn’t know — instead of inventing garbage on the fly — like I see at times from GPT and the rest.
And it’s open-source with open weights (!)
Let’s check out all the amazing features in this release.
1. Agent-first behavior (designed to stay on task)
GLM-5 is positioned around what we developers call agent workflows — situations where the model has to plan, execute, check results, and continue working toward a goal instead of responding once and stopping.
The main improvement here isn’t personality or creativity. It’s consistency. The model is tuned to maintain context and direction over longer sequences of actions, which is essential if you want AI to handle real workflows instead of isolated prompts.
2. A true coding-focused model
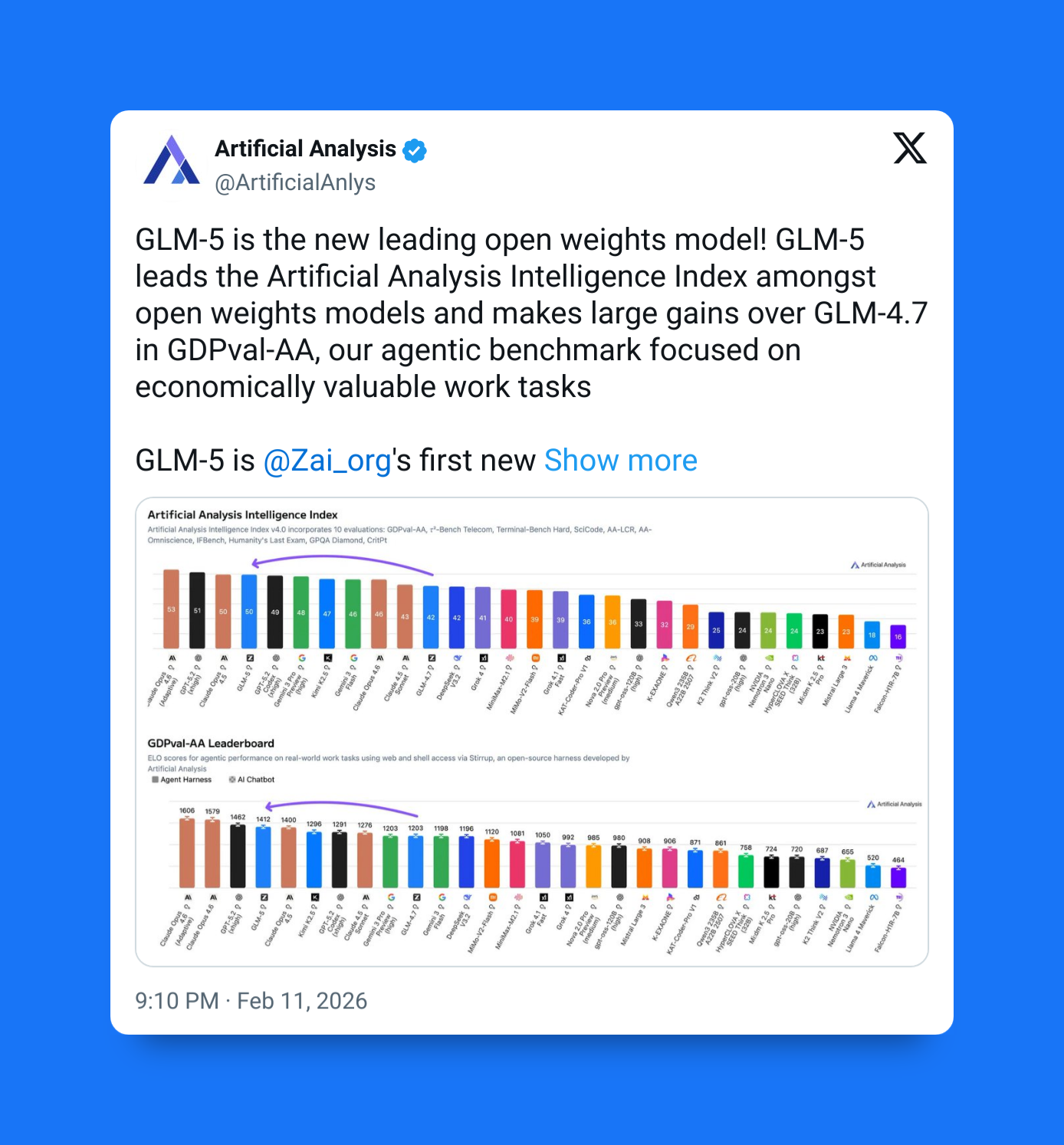
Software engineering is one the first and foremost priorities of this new model.
GLM-5 is optimized for working across larger codebases and longer development tasks rather than generating small snippets.
In practice this means keeping track of project structure, following constraints across files, and iterating toward working solutions. Improvements in coding usually signal broader gains in reasoning and planning — since programming requires precision and structured thinking.
3. Very large context window (so it can hold more of the problem at once)
GLM-5 supports an extremely long context lengths of 200,000 tokens — allowing large amounts of text, documentation, or code to stay visible to the model at once.
This matters more than it sounds. Instead of feeding information piece by piece, developers can provide entire specifications or large repositories in one session. That reduces fragmentation and makes long-running tasks far more stable.
4. Production-ready tool use
Another major focus is making the model usable inside real applications. GLM-5 includes features aimed at integration rather than conversation alone, such as:
- function calling for external tools or APIs
- structured outputs for predictable formatting
- streaming responses
- context caching for efficiency
- different reasoning modes for complex tasks
These features make it easier to embed the model into systems where it needs to coordinate with software rather than simply generate text.
5) The “slime” framework (the training story behind the behavior)
One of the more interesting additions sits behind the scenes. The slime framework is an open reinforcement-learning post-training system designed to make large-scale training more efficient.
Its purpose is to improve how models learn from feedback during long or complex interactions.
Instead of only learning from static examples, the model can be refined through iterative training setups that resemble real workflows. That kind of training infrastructure is closely tied to improvements in stability and long-task performance.
In simple terms, slime helps train models to behave better over time, not just answer individual questions well.
6) Efficient long-context architecture
GLM-5 also uses newer attention techniques designed to keep long-context performance manageable in terms of compute cost. Long context is useful only if it remains practical to run, so part of the engineering effort goes into maintaining efficiency while scaling capability.
This reflects a broader trend in AI development: smarter architecture choices instead of only increasing size.
7) Hardware and ecosystem implications
Another reason GLM-5 has drawn attention is that it was developed with deployment in mind on domestically produced AI chips. That makes it notable beyond technical capability, since it signals growing independence from the traditional hardware stack that has dominated AI training and inference.
GLM-5 isn’t mainly about sounding smarter in conversation.
Its significance comes from where it points the industry next: models designed to manage complexity over time. Long context, structured tool use, reinforcement learning infrastructure like slime, and strong coding ability all serve the same goal — making AI systems that can carry work from start to finish rather than stopping at the first response.