Unbelievable. Just unbelievable.
If you heard even a slice of all the crazy things that Claude Mythos has been doing in the wild — then you’ll understand why this was far far from just another incremental upgrade.
Because this is basically Claude Mythos — but actually made less powerful on purpose to avoid serious problems(!!)

Every ability went up drastically — this is hands-down the best (publicly available) coding model in the world right now. It’s not even close.

Imagine going from 54.5% to 98.5% in a major ability in just one release? How is that even possible.
For the computer-use work that sits at the heart of XBOW’s autonomous penetration testing, the new Claude Opus 4.7 is a step change: 98.5% on our visual-acuity benchmark versus 54.5% for Opus 4.6. Our single biggest Opus pain point effectively disappeared…
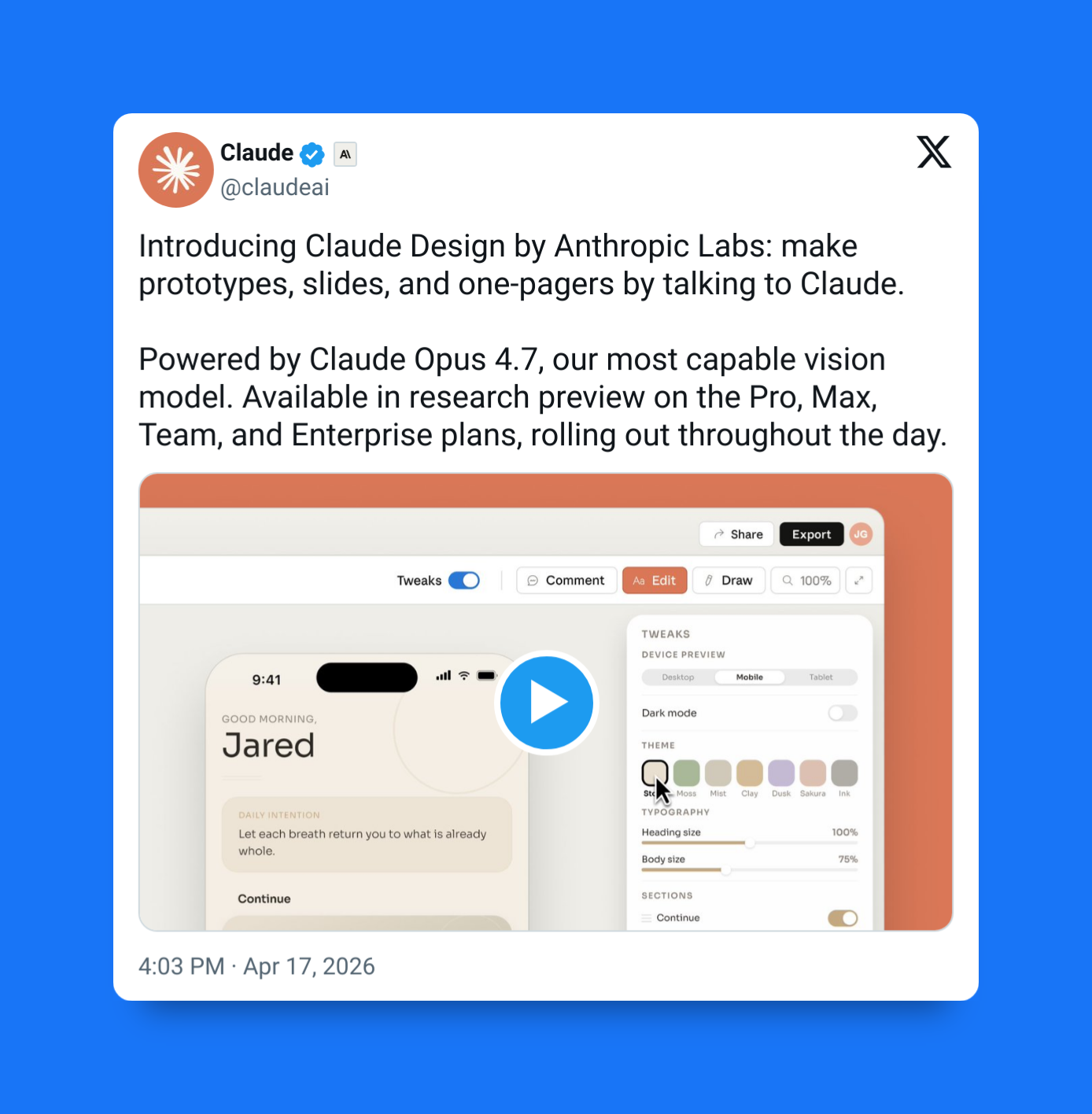
And should we talk about Claude Design? The shocking new Claude Opus 4.7-powered tool for creating any interactive diagram or slide from a text prompt…


1. Claude Mythos-lite
It’s been the absolute talk of the town in the days leading up this new Opus.
Earlier this month Anthropic revealed Claude Mythos Preview — an internal cybersecurity-focused model with capabilities too sensitive for broad public release.
Mythos could identify and exploit zero-day vulnerabilities across major operating systems and browsers. It reportedly found bugs 10 to 20 years old, including a 27-year-old OpenBSD vulnerability.

It also posted striking benchmark numbers:
- 83.1% on CyberGym vulnerability reproduction
- 595 crashes on internal exploit benchmarks
- 10 tier-5 control-flow hijacks on patched targets
“Mythos Preview identifies and exploits zero-day vulnerabilities across every major operating system and browser family.”
Mythos access was restricted to select defensive organizations through Project Glasswing.
Opus 4.7 is effectively the “safe” version — Anthropic intentionally nerfed its hacking capabilities while keeping its reasoning and coding skills at a “frontier” level for the public
2. Massive gains in agentic coding
It’s gotten so much better at reasoning across tasks, use tools, fix mistakes, and continue working until the objective is complete.
And self-verifying its own work too.
“Opus 4.7 pays closer attention to your instructions and devises ways to verify its own outputs before reporting back.”
That means stronger behavior such as:
- Writing tests before finalizing code
- Catching failed assumptions
- Revising broken implementations
- Managing multi-step workflows
So many companies have already been talking about all the positive impacts this has been having on their workflow.
- CursorBench: 70% vs 58% for Opus 4.6
- GitHub internal benchmark: 13% better task resolution than Opus 4.6
- Notion: +14% on complex workflows
- Bolt: up to 10% better on long app-building tasks
3. Better instruction fidelity
A subtle but important upgrade:
Opus 4.7 is more literal.
Older models often guessed what users meant. Sometimes helpful, often messy.
Opus 4.7 follows prompts more directly, making it stronger for structured engineering systems, automation pipelines, and reproducible workflows.
“Prompts written for previous models may produce different results because Opus 4.7 is less likely to infer unstated requests.”
Benefits include:
- More predictable outputs
- Less prompt drift
- Fewer hidden assumptions
- Better reliability in production
The tradeoff? Sloppy prompts may fail faster.
4. Unprecedented vision upgrades that actually matter
Anthropic also significantly improved image understanding.
Supported image resolution increased from 1,568 px to 2,576 px on the long edge, allowing Opus 4.7 to process far more visual detail.
“This is the first Claude model with high-resolution image support.”
That matters for:
- UI screenshots
- Dense dashboards
- Technical diagrams
- Multi-column PDFs
- Tables and charts
One partner benchmark reported:
- 98.5% visual acuity for Opus 4.7
- 54.5% for Opus 4.6
If you build AI tools that interact with interfaces or documents, this is a major upgrade.
5. New API controls for deeper thinking
Anthropic also changed how developers tune the model.
The headline addition is xhigh effort, a mode that trades speed for deeper reasoning.
“Anthropic recommends xhigh for most coding and agentic use cases.”
Use cases:
- Standard for light tasks
- High for serious reasoning
- xhigh for debugging large systems or complex audits
At the same time, older knobs like temperature, top_p, and top_k no longer accept custom non-default values on Opus 4.7.
That signals a new philosophy: less randomness tuning, more compute-based reasoning control.
7. The catch: tokenizer costs
Pricing stayed the same:
- $5 / million input tokens
- $25 / million output tokens
But Anthropic introduced a new tokenizer.
The same text may now use 10% to 35% more tokens than before.
“The same fixed text may tokenize to approximately 1.0x–1.35x the tokens used by Opus 4.6.”
So while rates stayed flat, real usage costs may rise — especially for long contexts, agent loops, or document-heavy workflows.
Claude Opus 4.7 is serious release for software developers.
It improves where it matters most:
- Agentic coding
- Self-verification
- Better prompt fidelity
- Stronger vision
- Deeper reasoning controls
And it arrives right after Anthropic showed a stronger model it chose not to release publicly.
That alone tells you something important:
The next generation of AI is already here.