This new AI coding agent from Google is unbelievable
Wow this is insane.
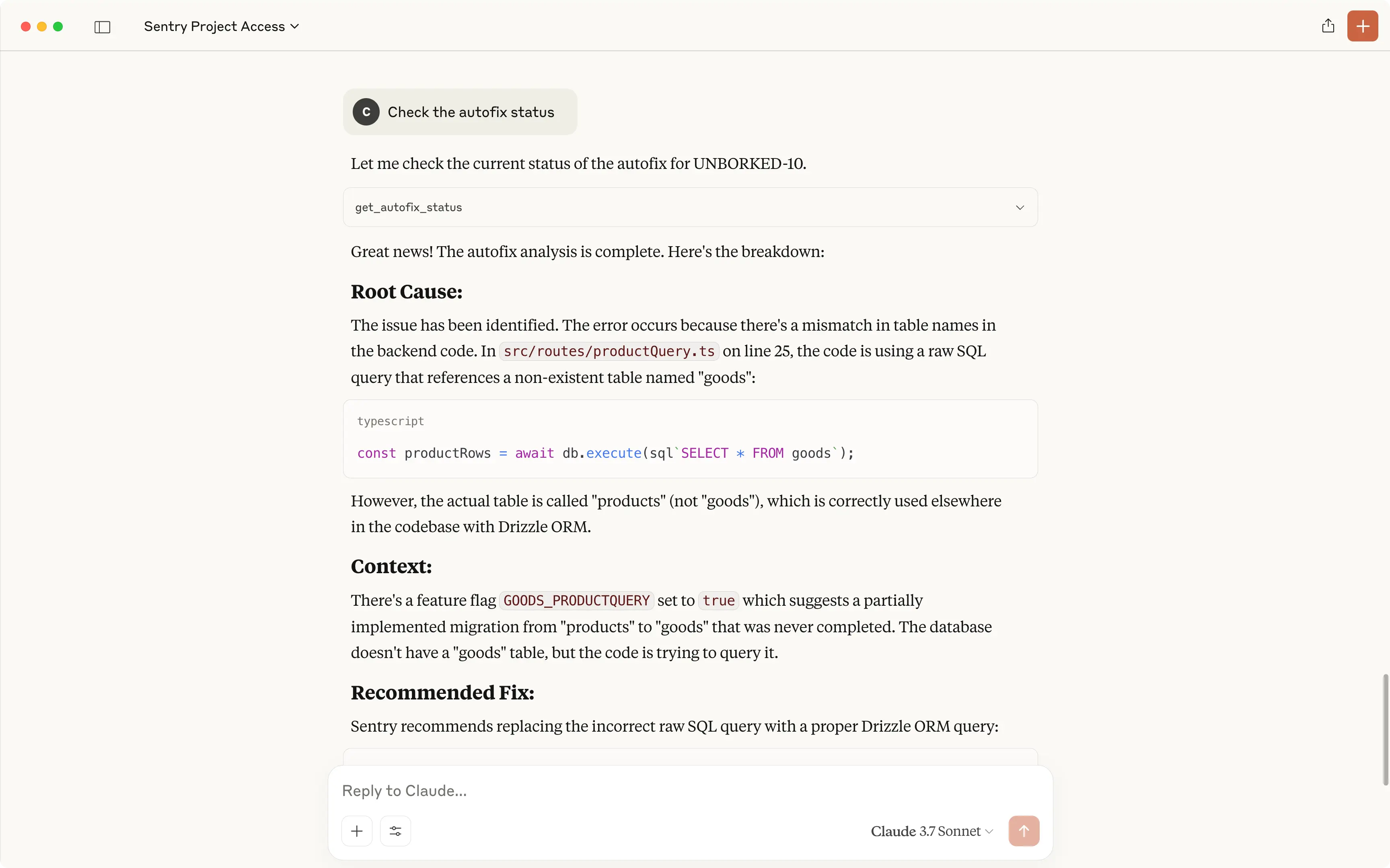
This new AI coding agent from Google is simply incredible. Google is getting dead serious about dev tooling. No more messing around.
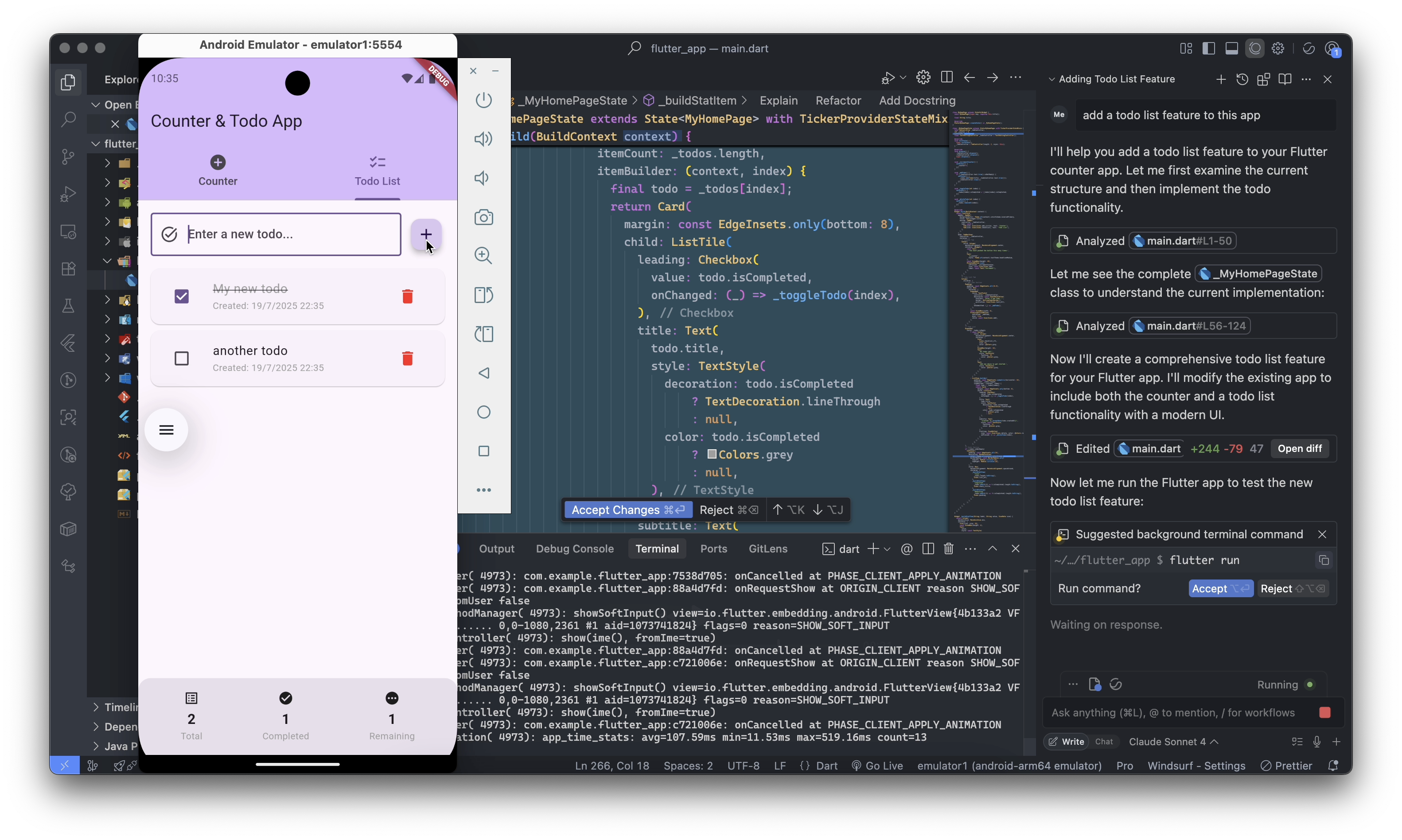
Jules is a genius agent can understand your intent, plan out steps, and execute complex coding tasks without even trying.
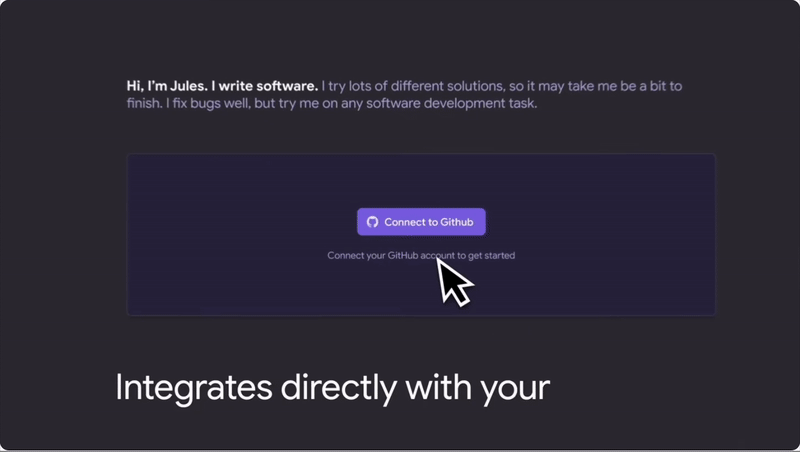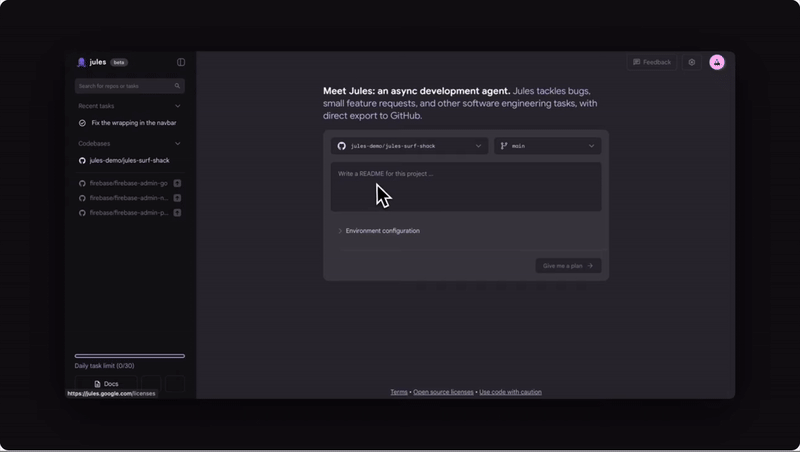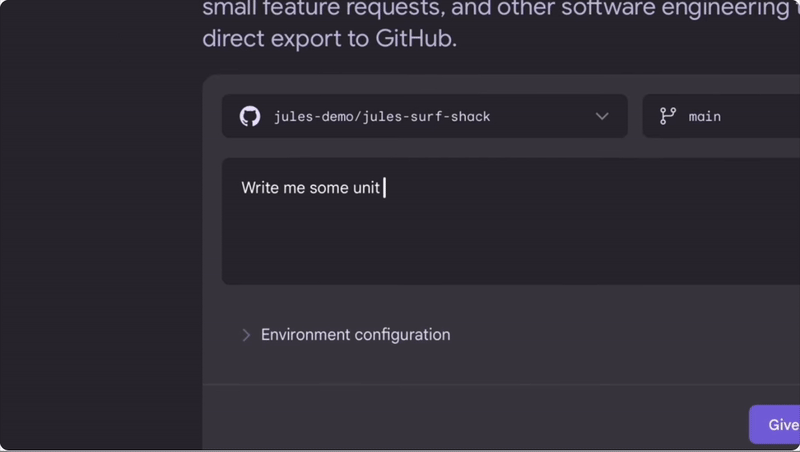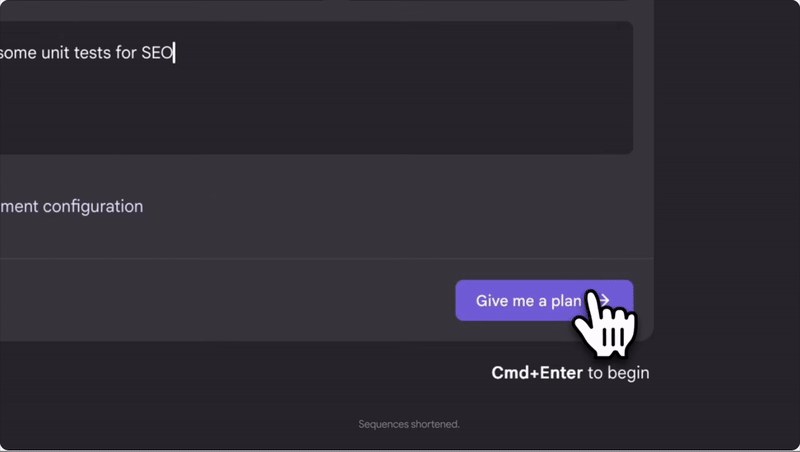
A super-smart teammate who can tackle coding tasks on its own asynchronously to make software dev so much easier.
It works seamlessly in the background so you can focus on other important stuff.
Gemini 2.5 Pro
Jules is powered by Gemini 2.5 Pro, which is Google’s advanced AI model for complex tasks. This gives it serious brainpower for understanding code.
And you bet 2.5 Flash is on its way to give it even more insane speeds.
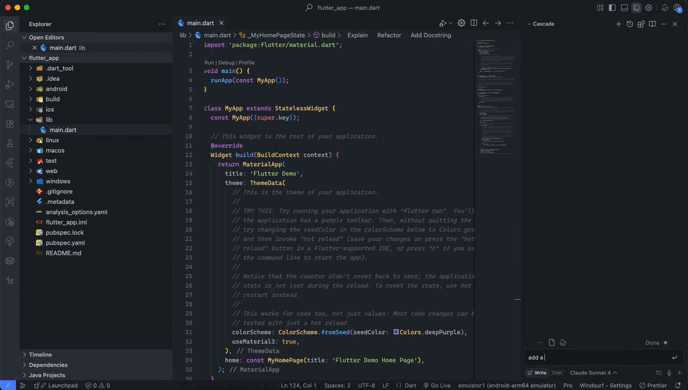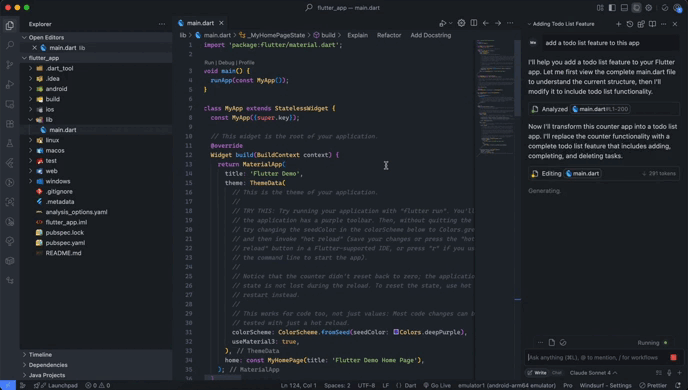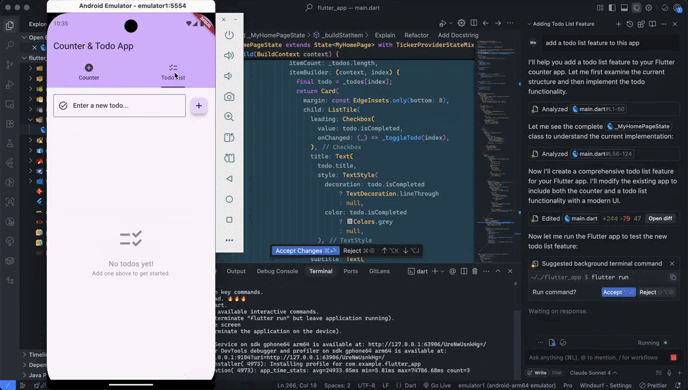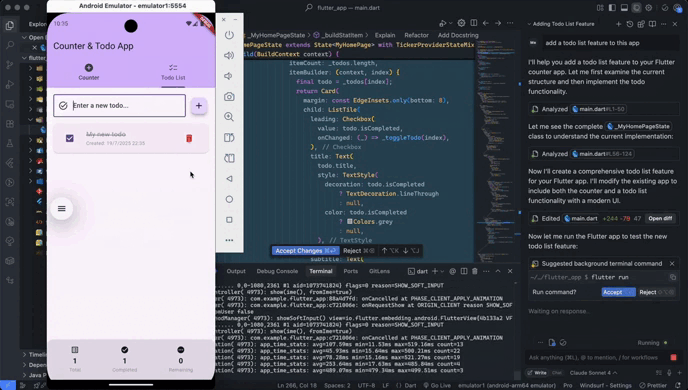
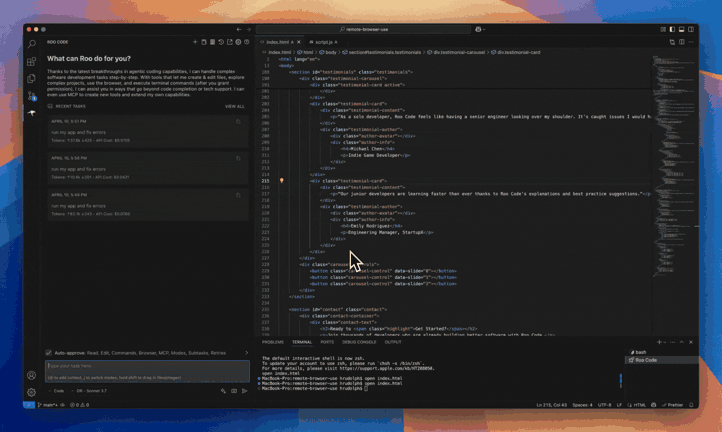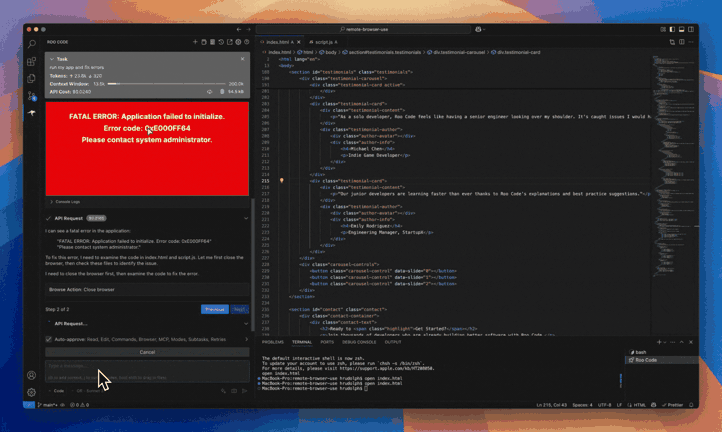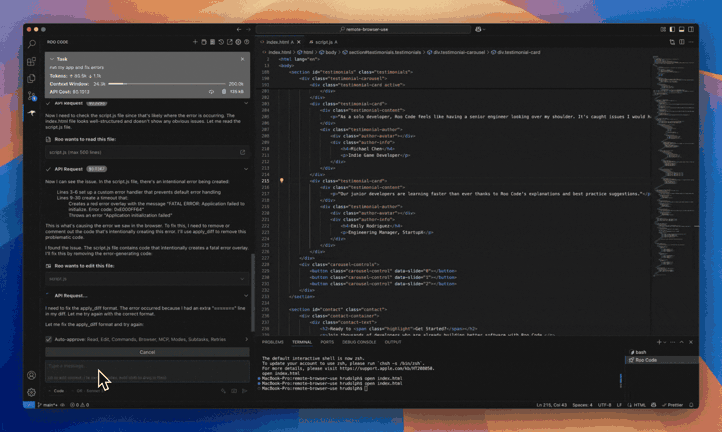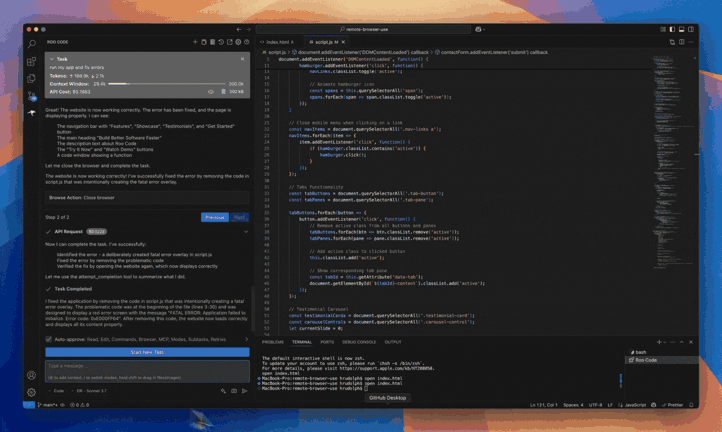
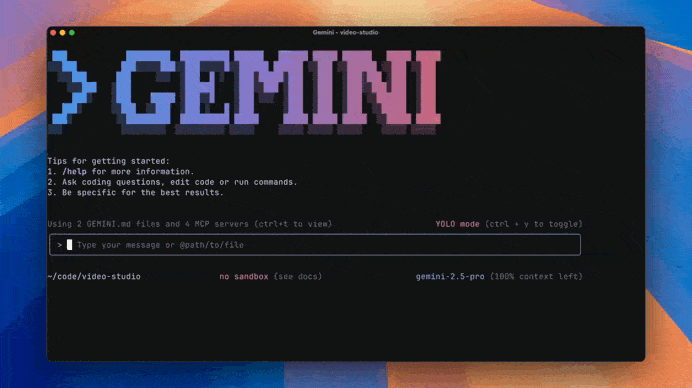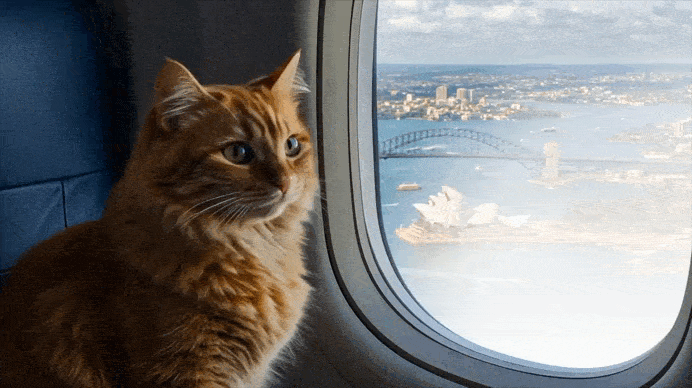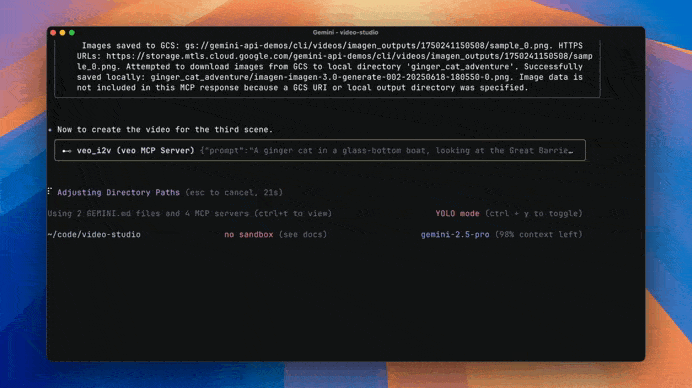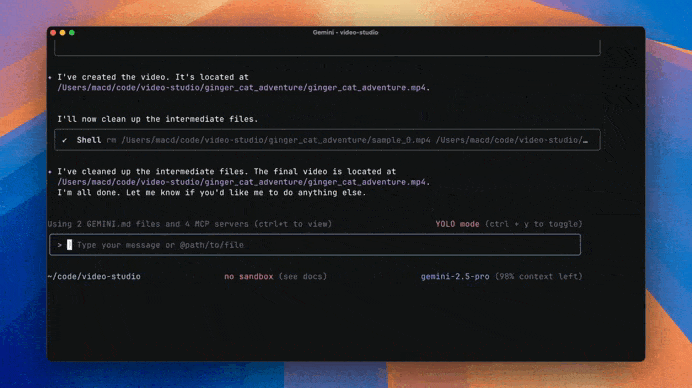
When you give Jules a task it clones your codebase into a secure virtual machine in the Google Cloud. This is like a private workspace where Jules can experiment safely without messing with your live code.
It then understands the full context of your project. This is crucial because it helps Jules make smart, relevant changes. It doesn’t just look at isolated bits of code; it sees the whole picture.
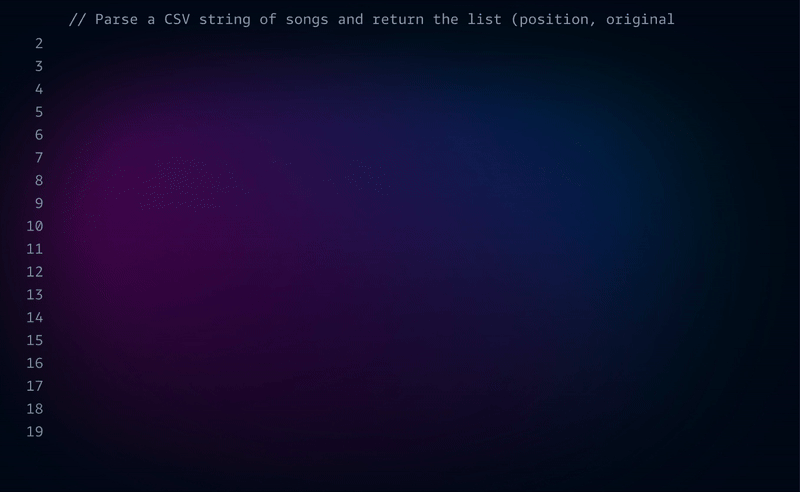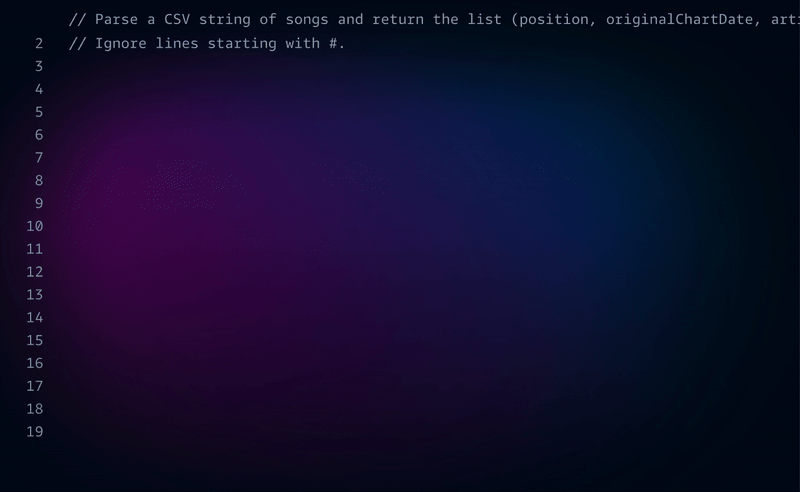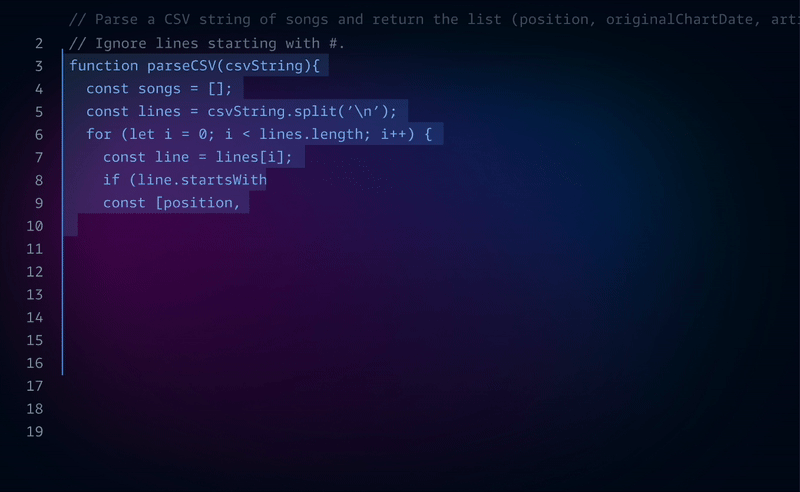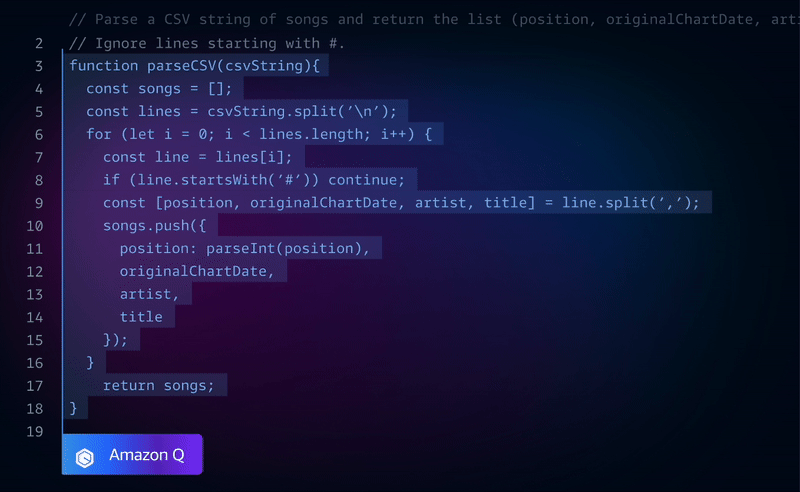
After it’s done, Jules shows you its plan, its reasoning for the changes, and a “diff” of what it changed. You get to review everything and approve it before it goes into your main project. It even creates pull requests for you on GitHub!
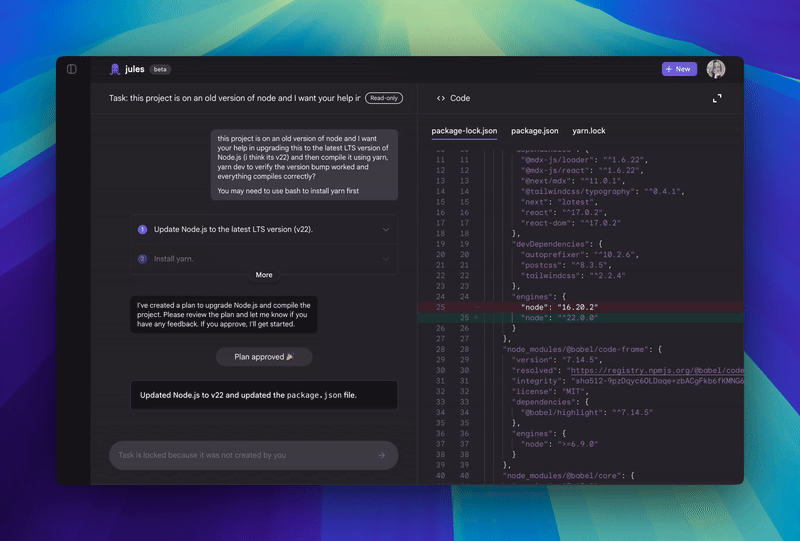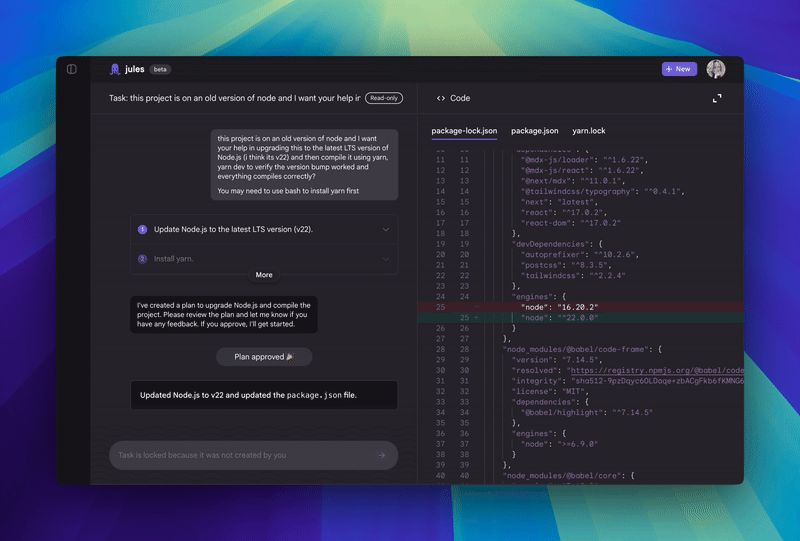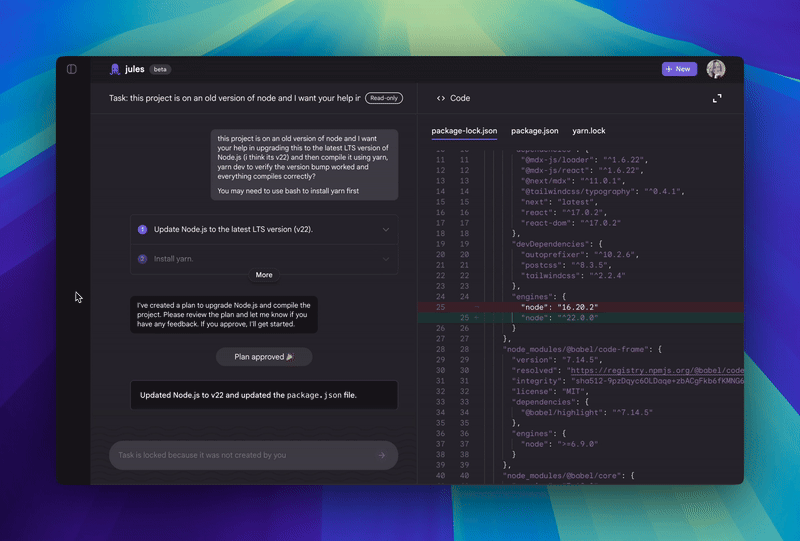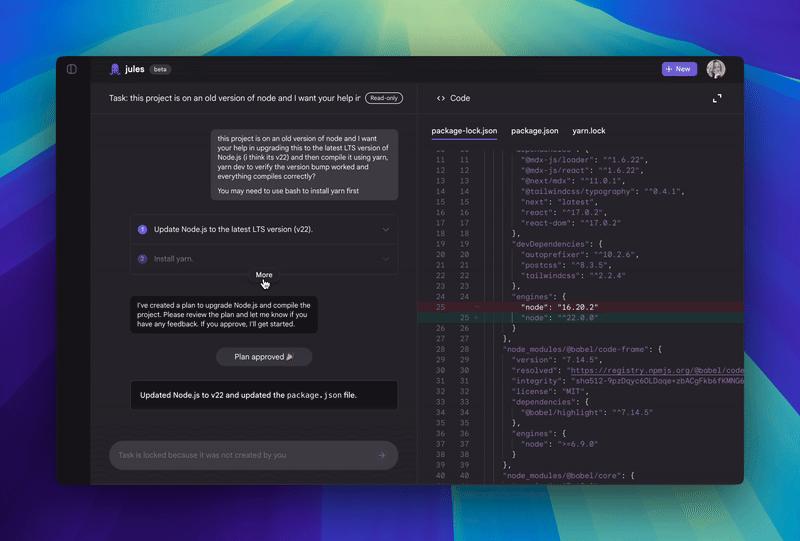
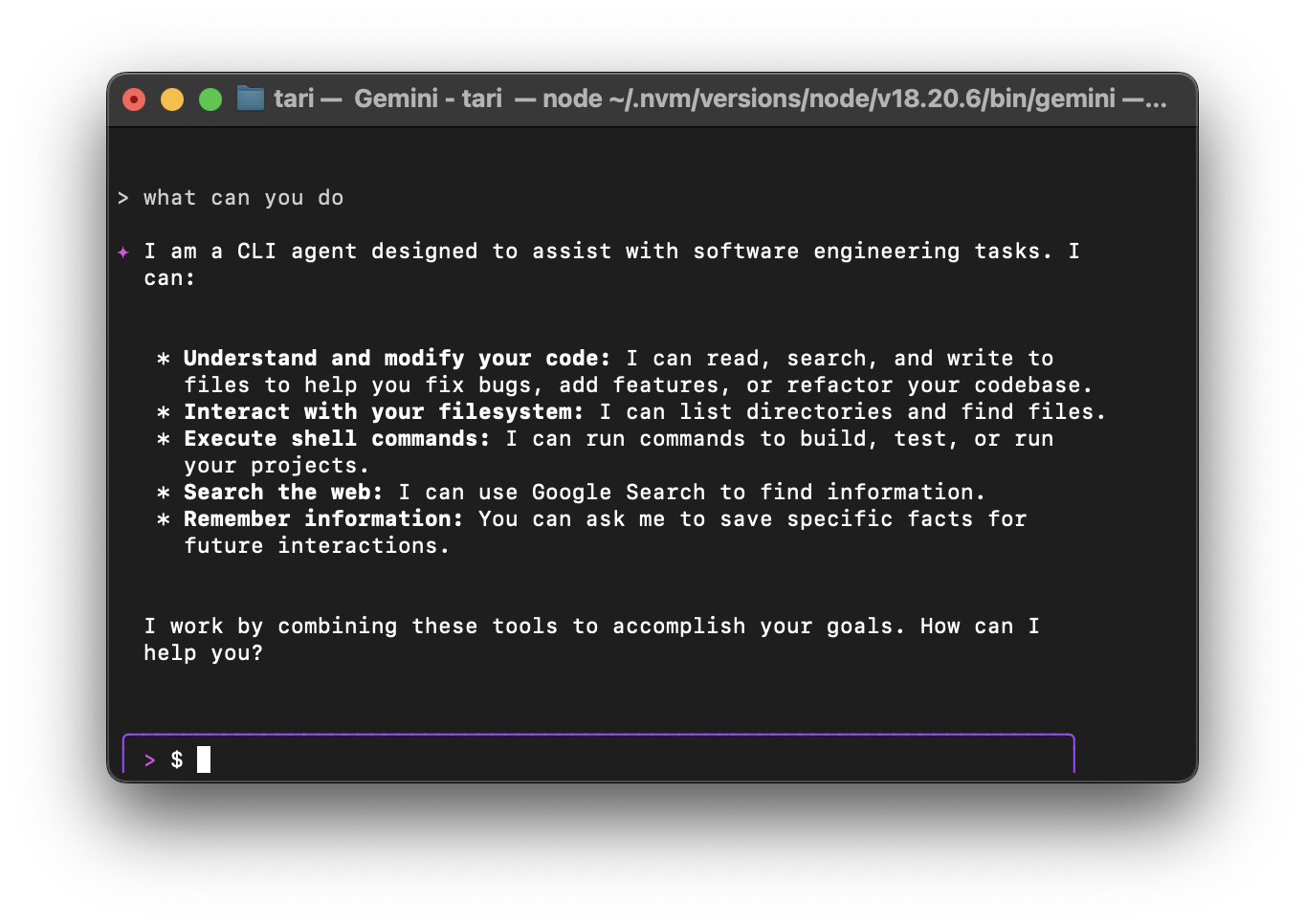
Jules is quite the multi-tasker. It can handle a variety of coding chores you might not enjoy doing yourself.
For example, it can write tests for your code, which is super important for quality. It can also build new features from scratch, helping you speed up development.
Bug fixing? Yeah Jules can do that too. It can even bump dependency versions, which can be a tedious and error-prone task.
One cool feature is its audio changelogs. Jules can give you spoken summaries of recent code changes, turning your project history into something you can simply listen to.
Google has made it clear that you’re always in charge. Jules doesn’t train on your private code, and your data stays isolated. You can review and modify Jules’s proposed plans at every step.
It works directly with GitHub, so it integrates seamlessly with your existing workflow. No need to learn a new platform or switch between different tools.
Jules is currently in public beta, and it’s free to use with some limits. This is a big step towards “agentic development,” where AI systems take on more responsibility in the software development process.
It might sound like Jules is coming for developer jobs, but that’s probably not the goal here — at least for now.
Jules is meant to be a powerful tool that frees up developers to focus on higher-level thinking, design, and more creative problem-solving. It’s about making you more productive and efficient.
So, if you’re a developer, now’s a great time to check out Jules. It could really change the way you work.