A new era of models is here.
The age of speed vs intelligence is gone.
Smarter than Gemini 2.5 Pro + Faster than 2.5 Flash…
Gemini 3 Flash is here and it’s officially ending the era of the “lite” model.
A total reimagining of what a lightweight model can actually do.
This new Gemini 3 Flash is built on a new architecture that allows it to punch way above its weight class.


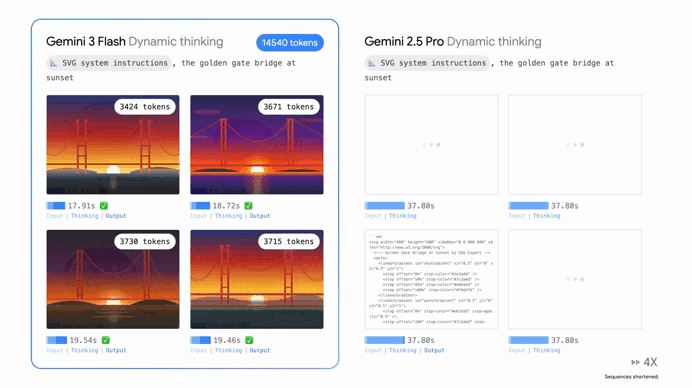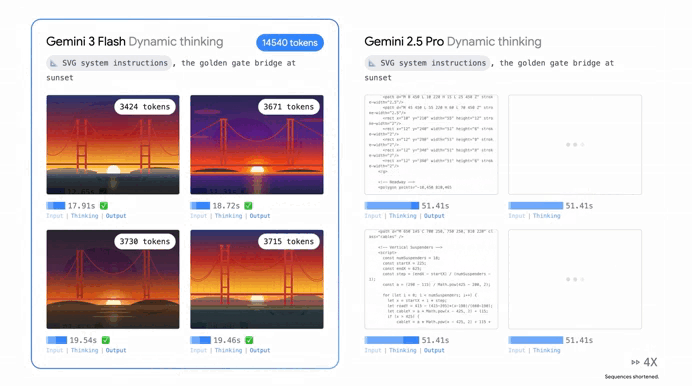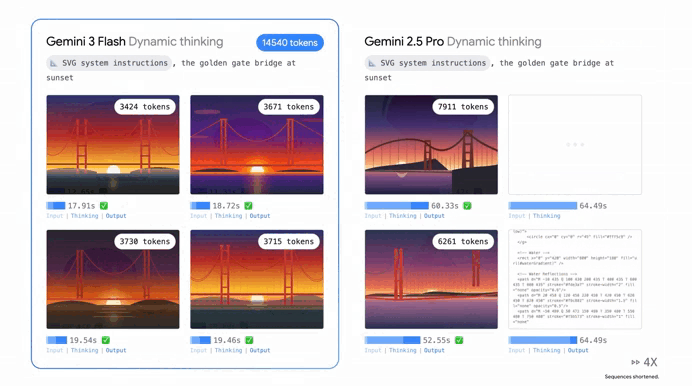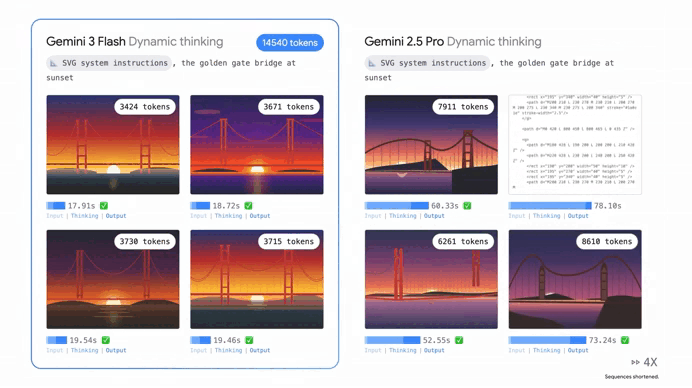
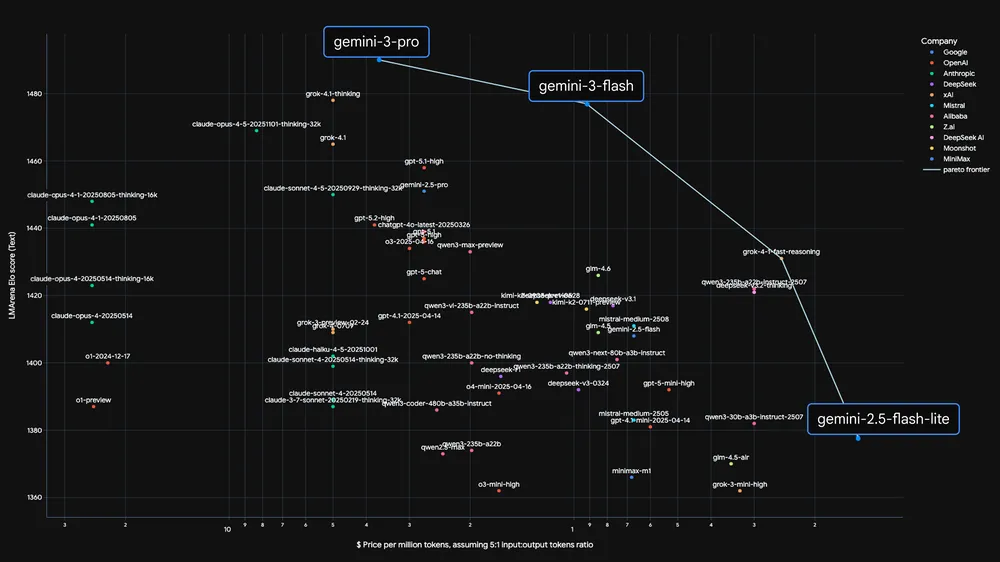
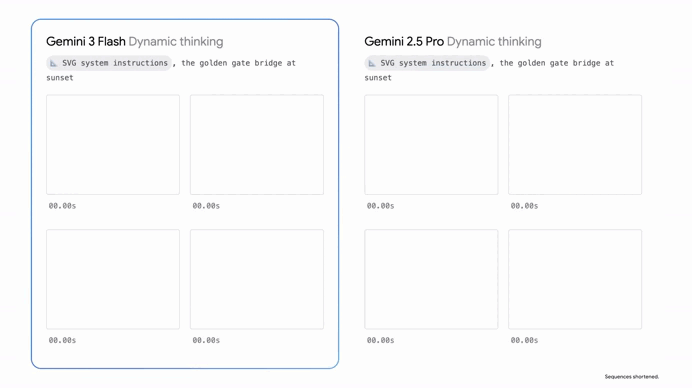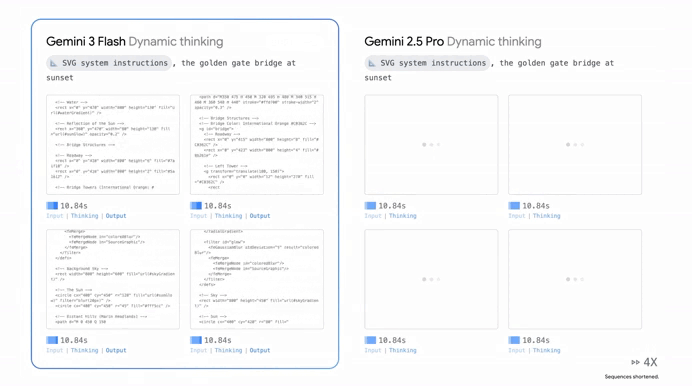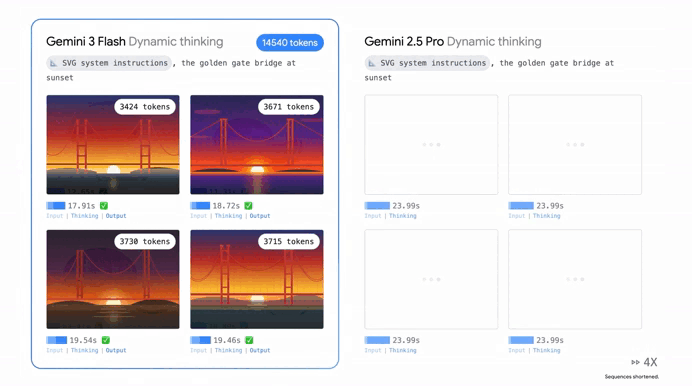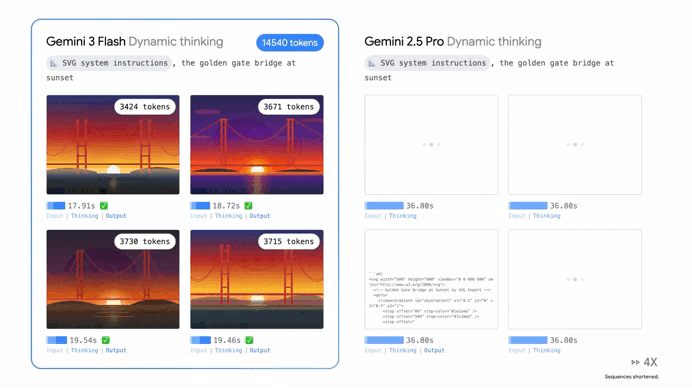
It’s absolutely outperforming Gemini 2.5 Pro in almost every way that matters.
When researchers put this model through its paces with PhD-level reasoning tests it scored a staggering 90.4%.
It’s now going toe-to-toe with the world’s most powerful frontier models — but it’s doing it in a fraction of the time.
Whether you’re asking it to solve a complex physics problem or help you debug a sprawling mess of code, it’s hitting marks that we didn’t think were possible for a “fast” model just six months ago. In coding it’s matching the Pro version’s performance, solving nearly 78% of complex software engineering tasks straight out of the box.
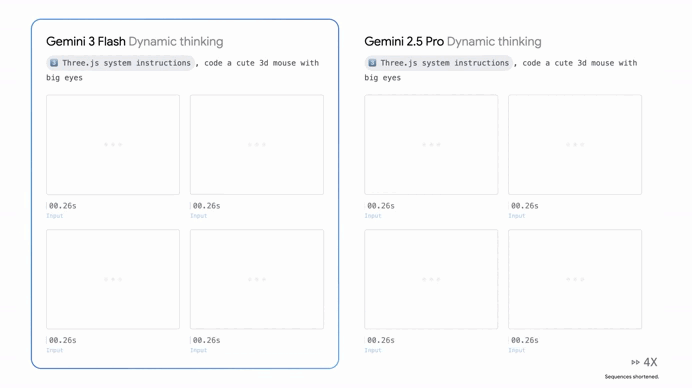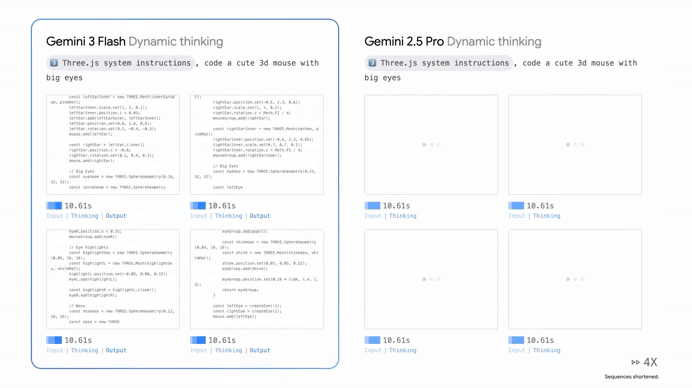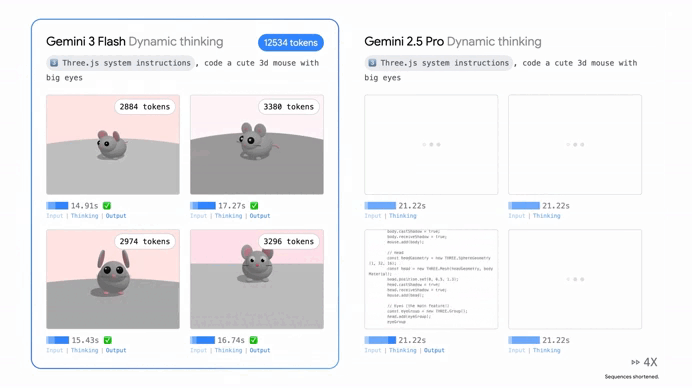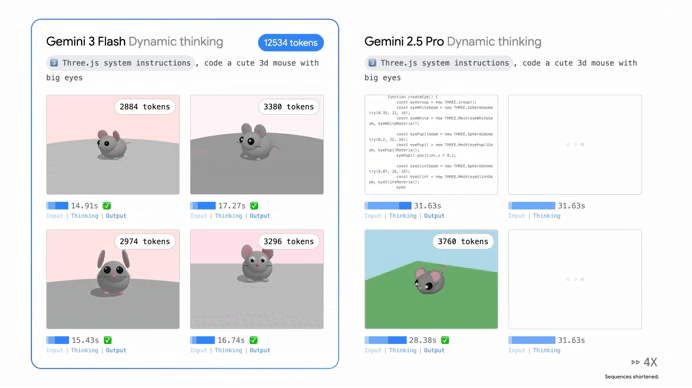
One of the coolest things about Gemini 3 Flash is that it doesn’t just “think” in one speed anymore. Google introduced something called “Thinking Levels,” which is essentially like giving the AI a manual transmission.
If you just need a quick email summary, the model stays in a low-intensity mode to give you an answer instantly. But if you throw a massive, multi-step logical puzzle at it, it shifts into a high-reasoning gear. In this mode, it uses “Thought Signatures” to map out its logic behind the scenes.
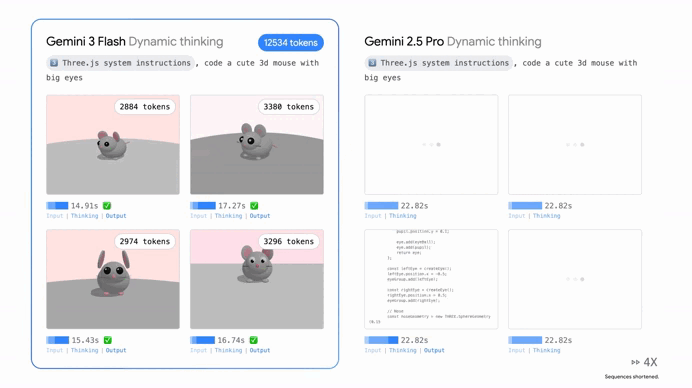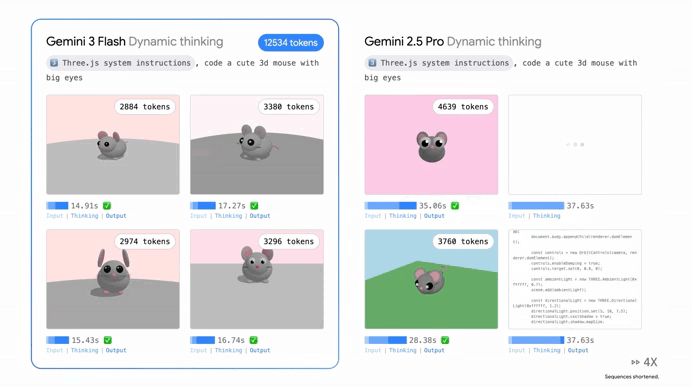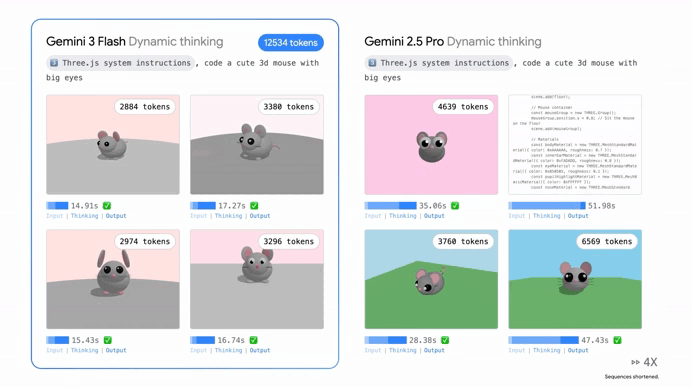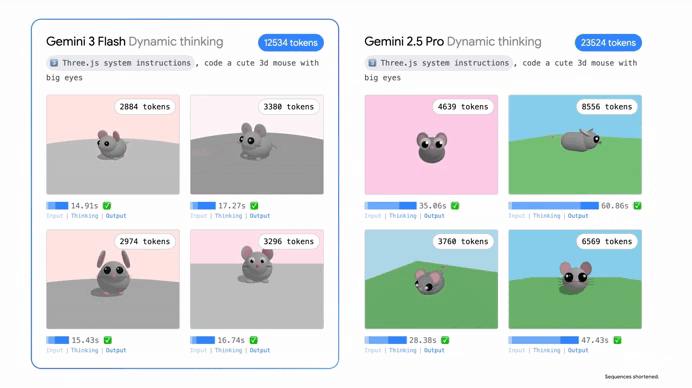
It’s like watching a master chess player visualize ten moves ahead before they ever touch a piece. This ensures that when the answer finally pops up on your screen, it’s not just a guess—it’s a verified, reasoned conclusion.
The visual side of things is just as wild. We’ve moved past the days where an AI could just tell you “that’s a picture of a cat.” Gemini 3 Flash has advanced spatial awareness.
You can show it a complex blueprint or a crowded warehouse photo, and it can “zoom in,” count specific items, or even tell you where a piece of equipment is located relative to everything else. It’s making the multimodal dream feel even more real, seeing the world with a level of detail that feels almost human.
But for the developers and businesses out there, the real game changer is the cost. Even though it’s smarter than the old Pro models, it’s priced at an incredibly low $0.50 per million input tokens.
Because the model is roughly 30% more efficient with how it uses language, you’re actually getting way more intelligence for every dollar you spend.
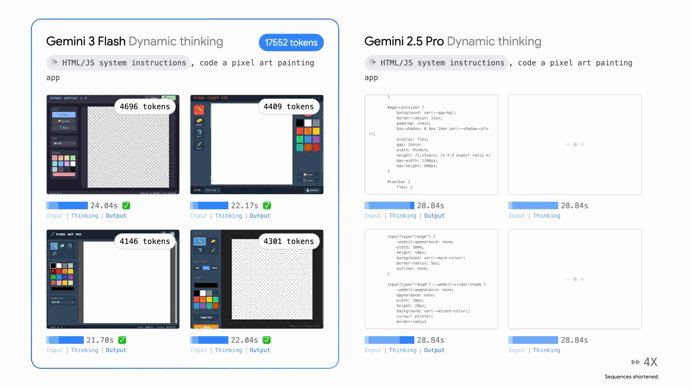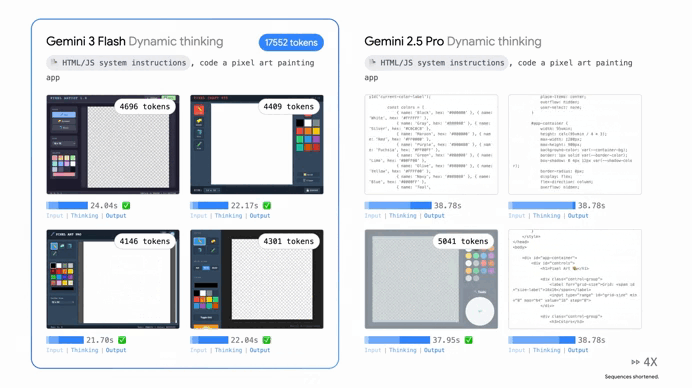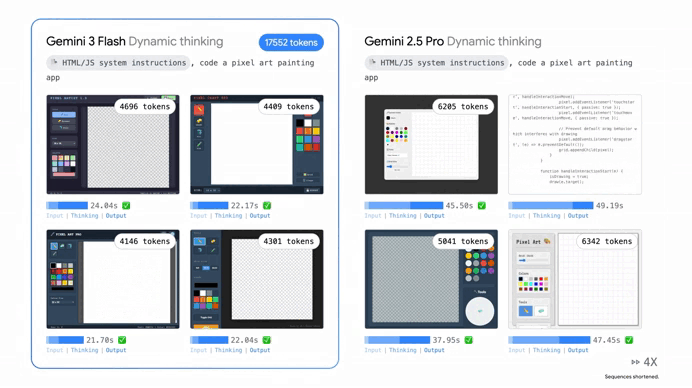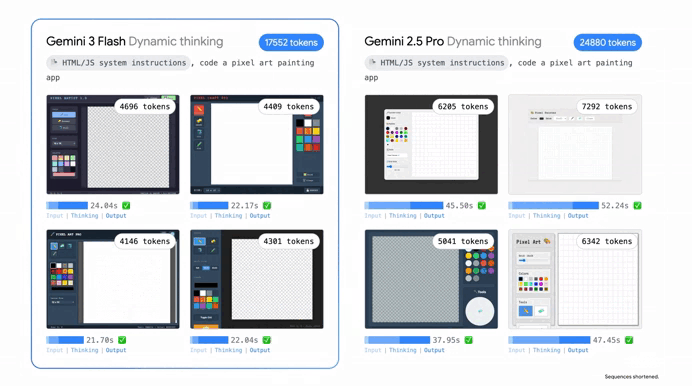
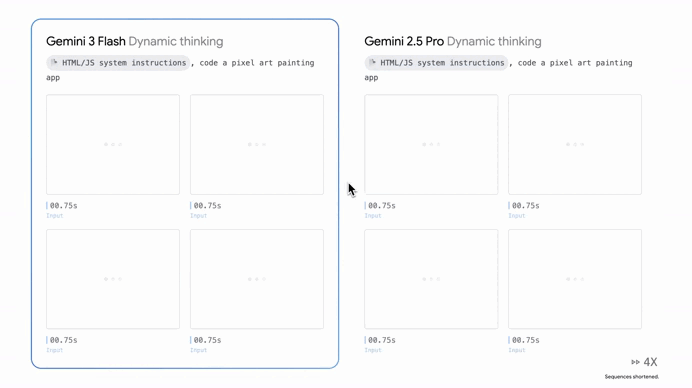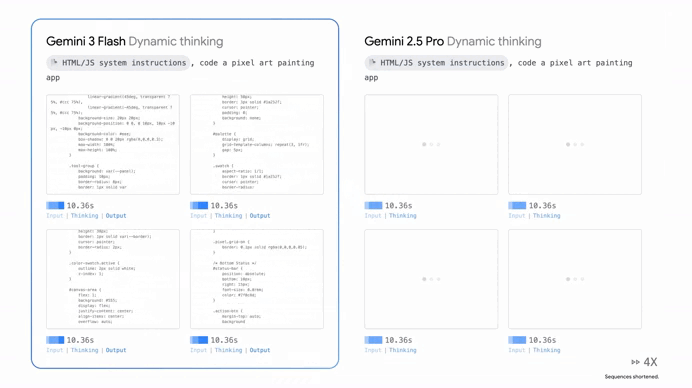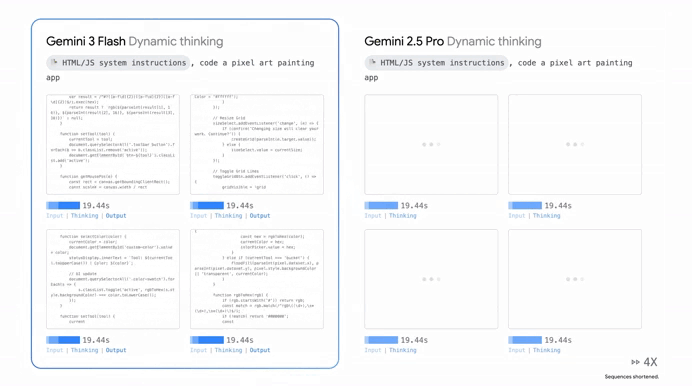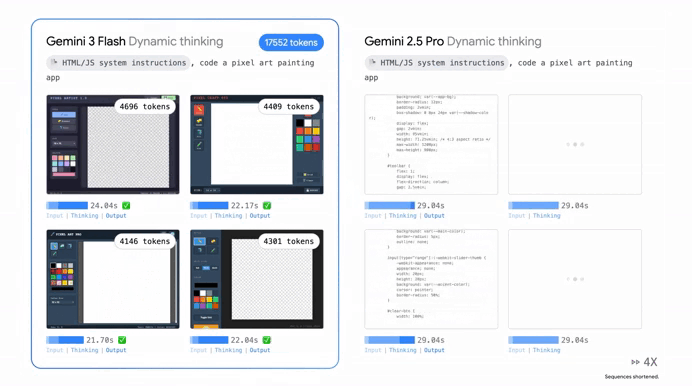
Plus with a context window of a full million tokens you can feed it entire libraries of documents or massive code repositories without it losing the plot.
At the end of the day, Gemini 3 Flash is proof that we’ve entered a new era. We’re no longer waiting for the “smart” models to get faster; the fast models have finally caught up and become the smart ones. It’s the new default for how we interact with AI—seamless, incredibly deep, and faster than you can blink.