This new IDE just destroyed VS Code and Copilot without even trying
Wow I never thought the day I stop using VS Code would come so soon…
But the new Windsurf IDE blows VS Code out of the water — now I’ve cancelled my GitHub Copilot subscription and made it my main IDE.
And you know, when they said it was an “Agentic IDE” I was rolling my eyes at first because of all the previous hype with agents like AutoGPT.
But Windsurf shocked me.


These agentic tools are going to transform coding for sure — and not necessarily for the better — at least from the POV of software devs 😅
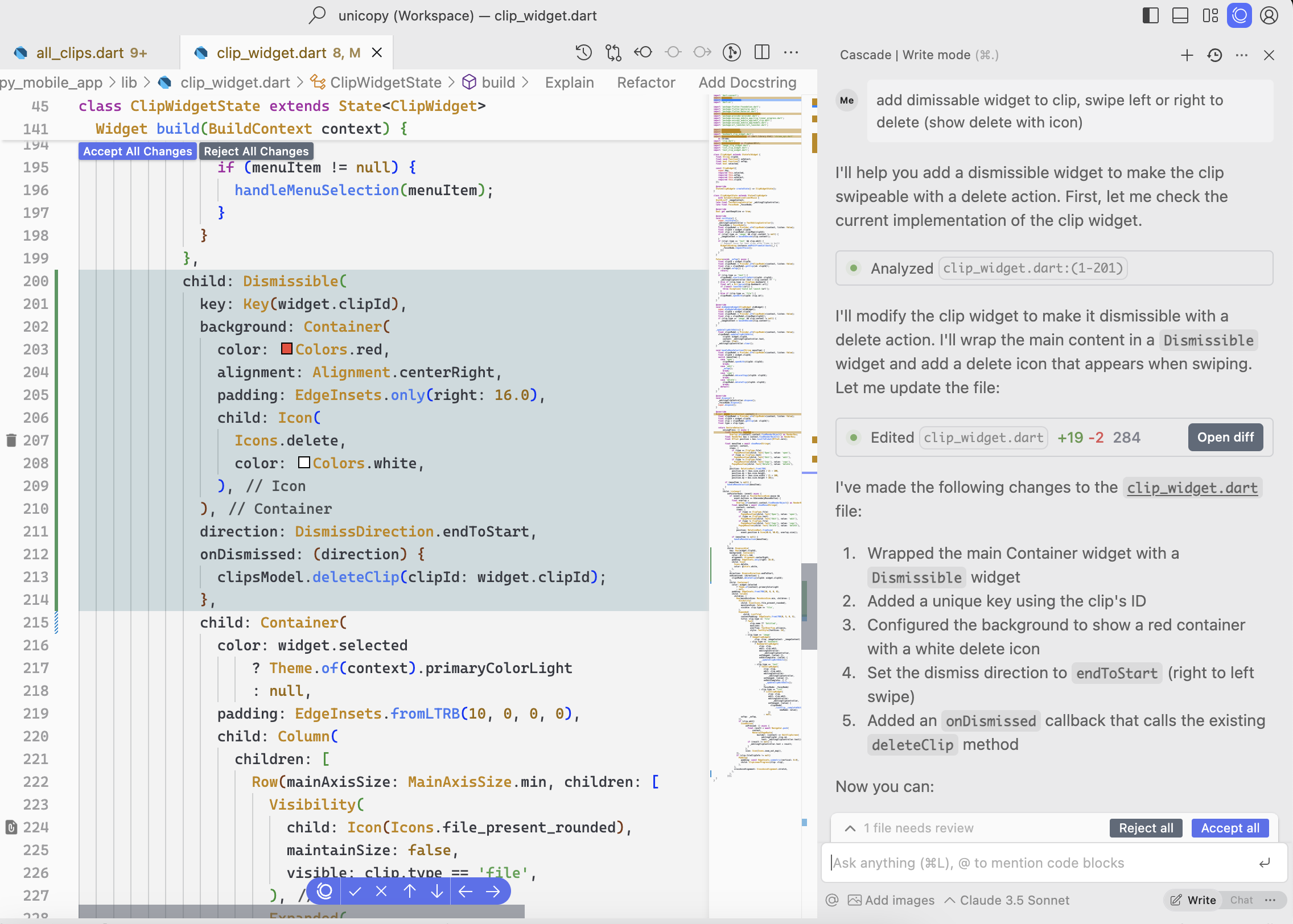
The agent actually makes useful changes to my code, and my prompt didn’t have to be so low-level. They call it Cascade and it saves so much time.

You see how it analyzes several areas in my code to make the changes — and this analysis can include many many files in your codebase.
And same for the changes — it’s doing the coding for you now.
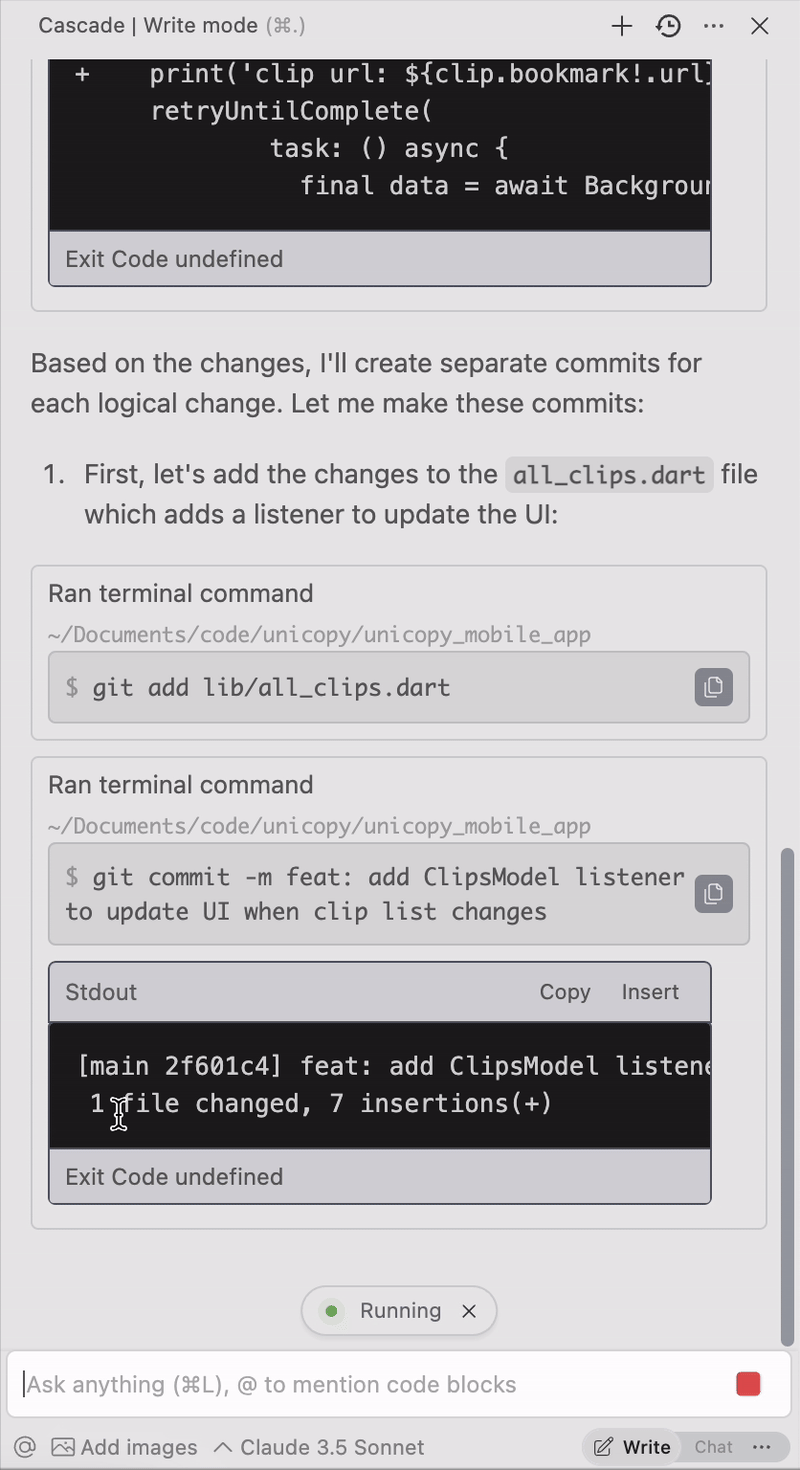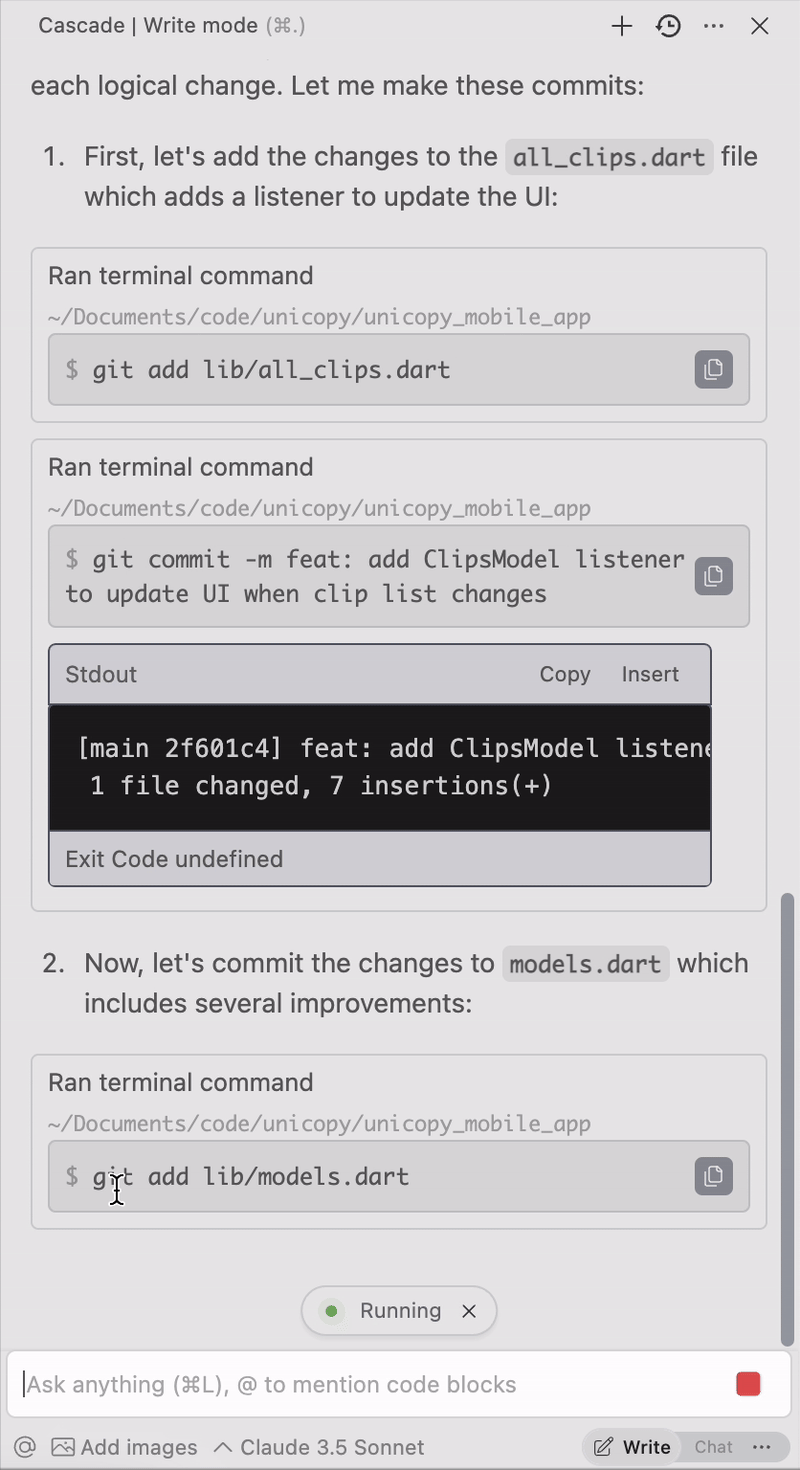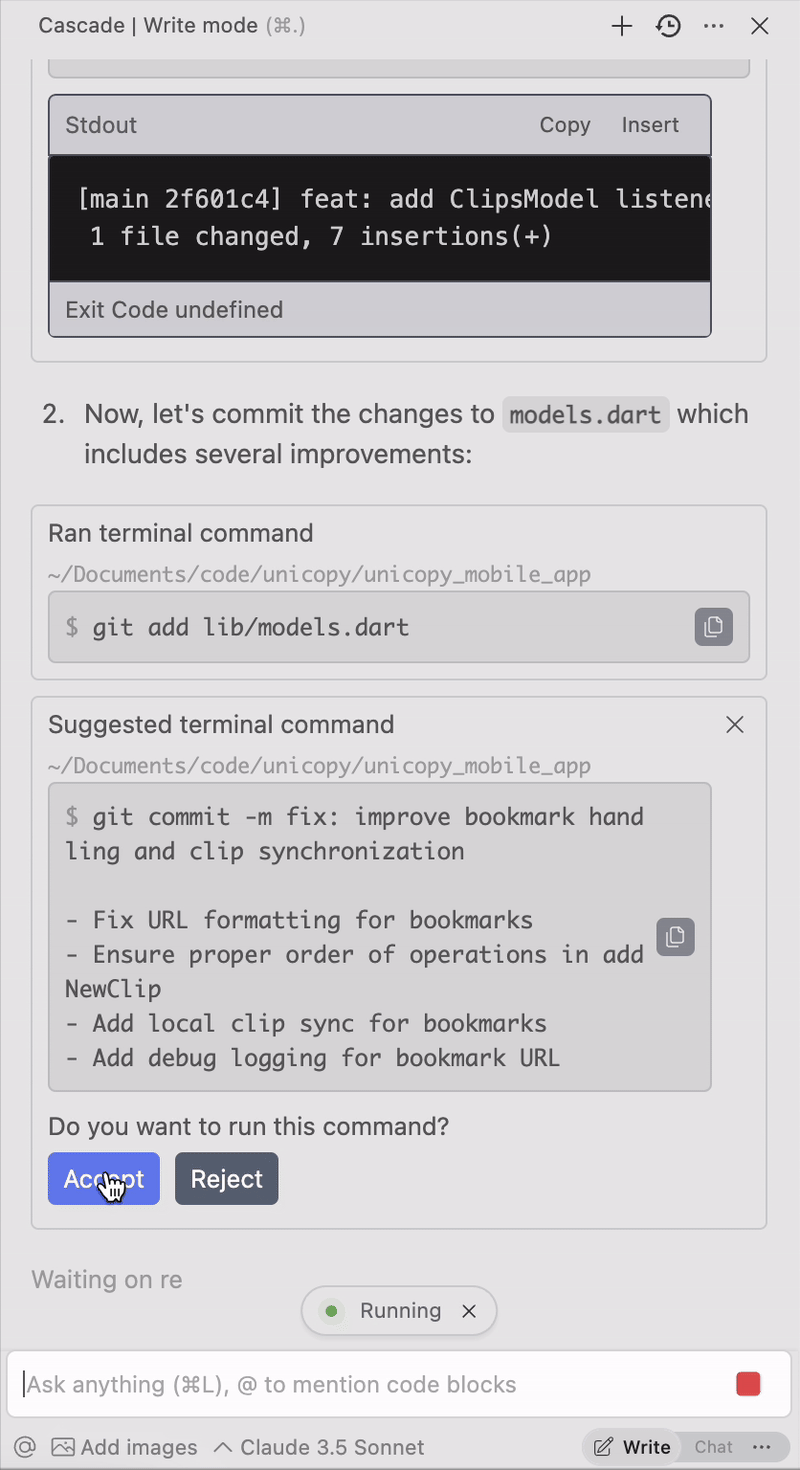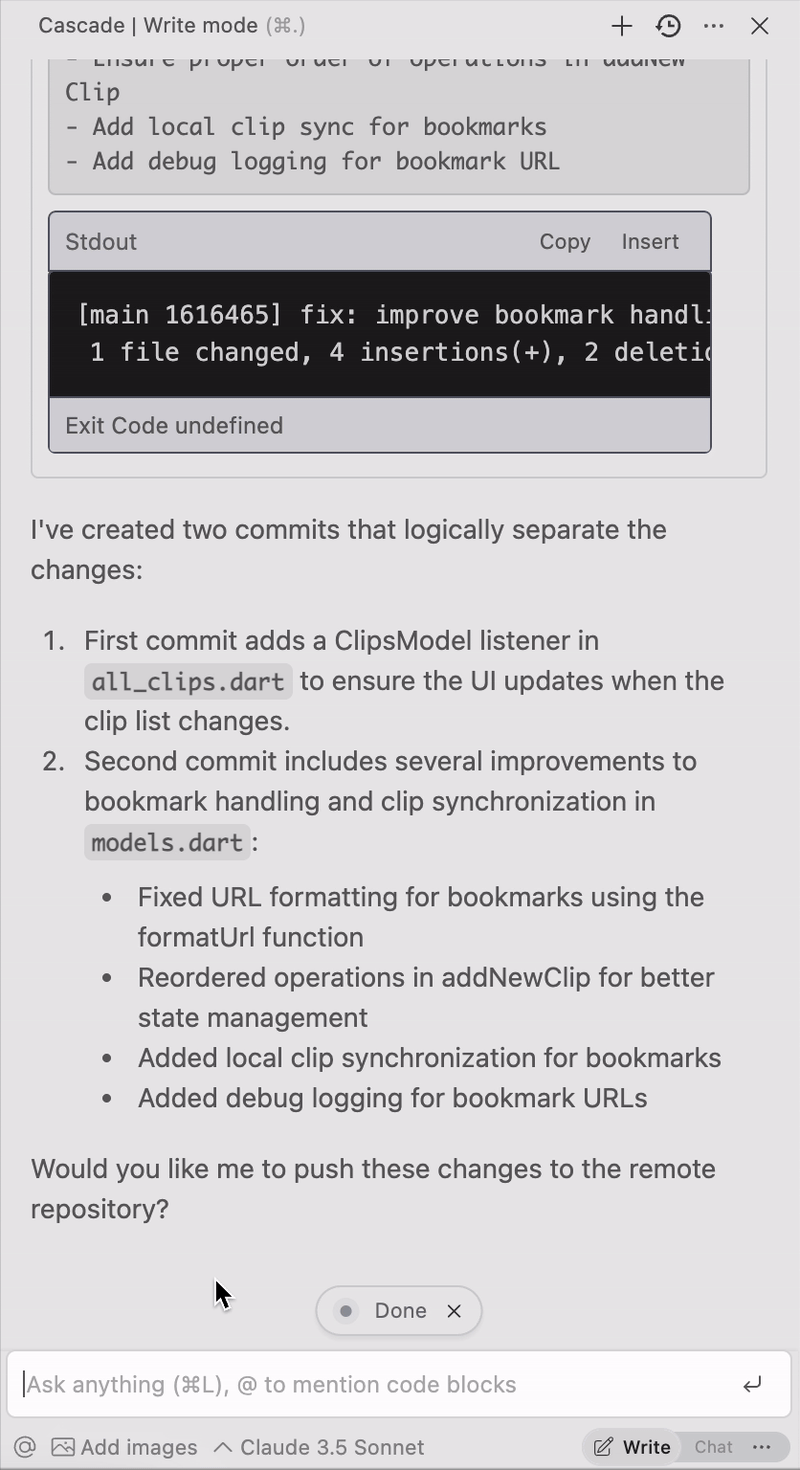
Save tons of time by telling it to write your commit messages for you:
Just like Copilot it gives you code completions — that’s just expected at this point — and they’re free.

But it goes way beyond that with Supercomplete — an incredible feature that predicts not just your next line, but your next intent.
Probably inspired by a similar feature in the Cursor IDE.
It doesn’t just complete your code where the cursor is, it completes your high-level action. It “thinks” at a higher level of abstraction.
Like when you rename a variable it’ll automatically know you want to do the same for all the other references.

And not just for one variable but multiple logically related ones — which goes beyond the “rename variable” function that editors like VS Code have.

When you update a schema in your code, it’ll automatically update all the places that use it — and not just in the same file.

And how about binding to event handlers in a framework like React? Doing it for you after you create the variable?
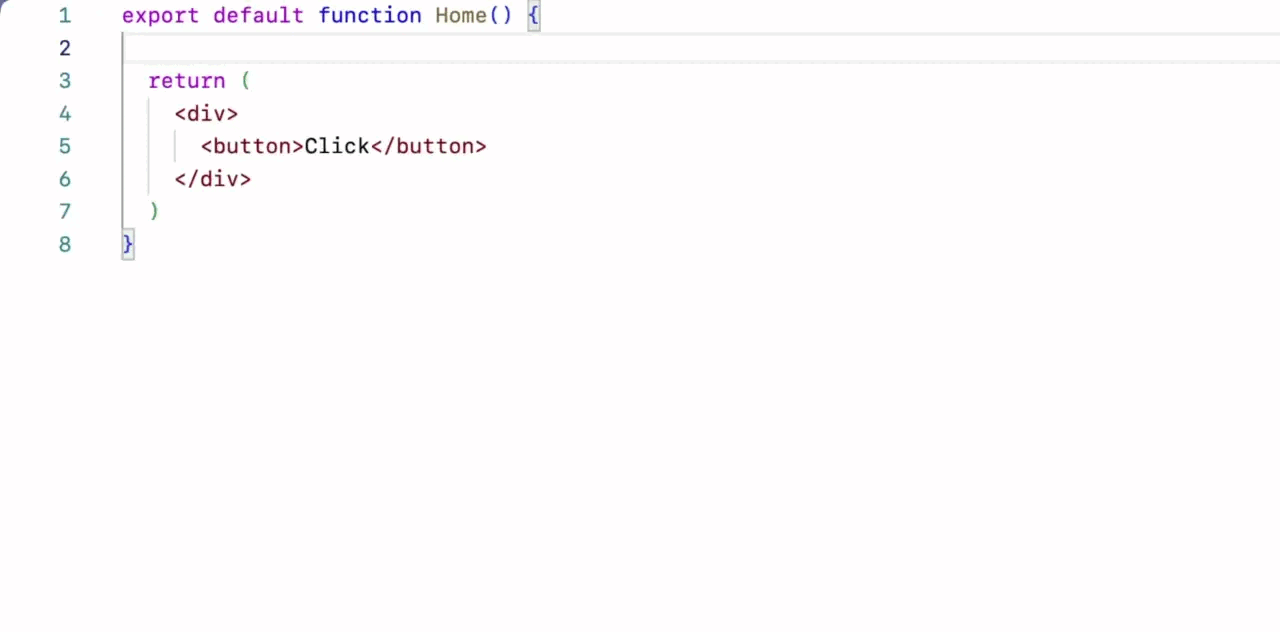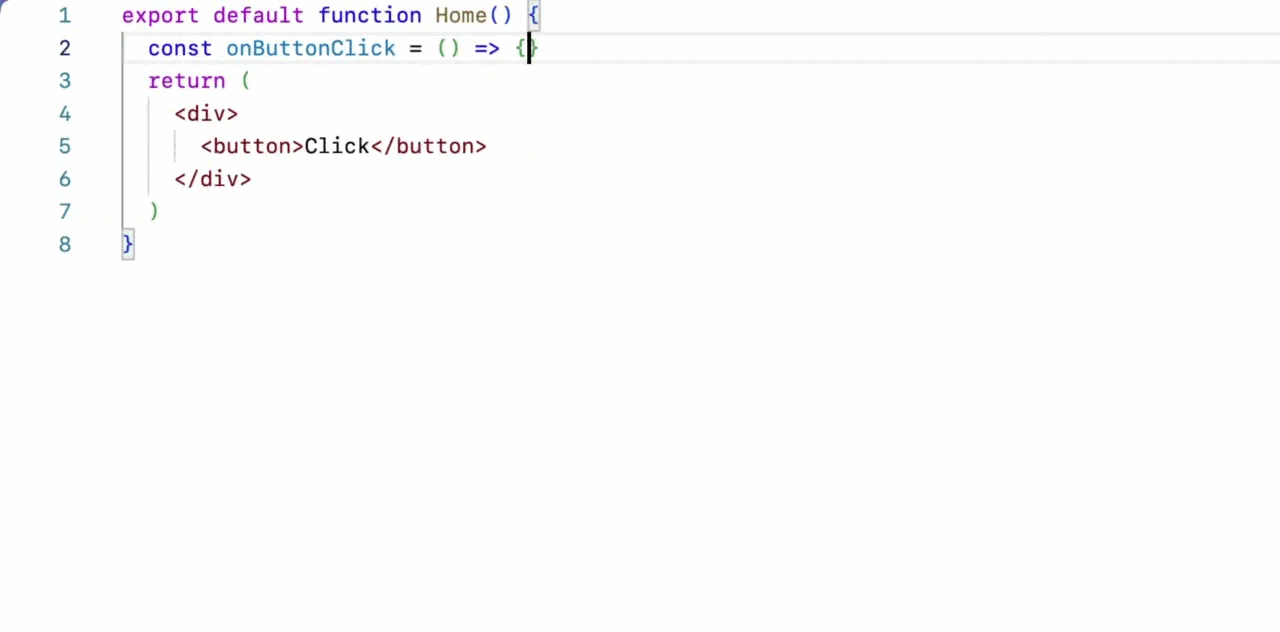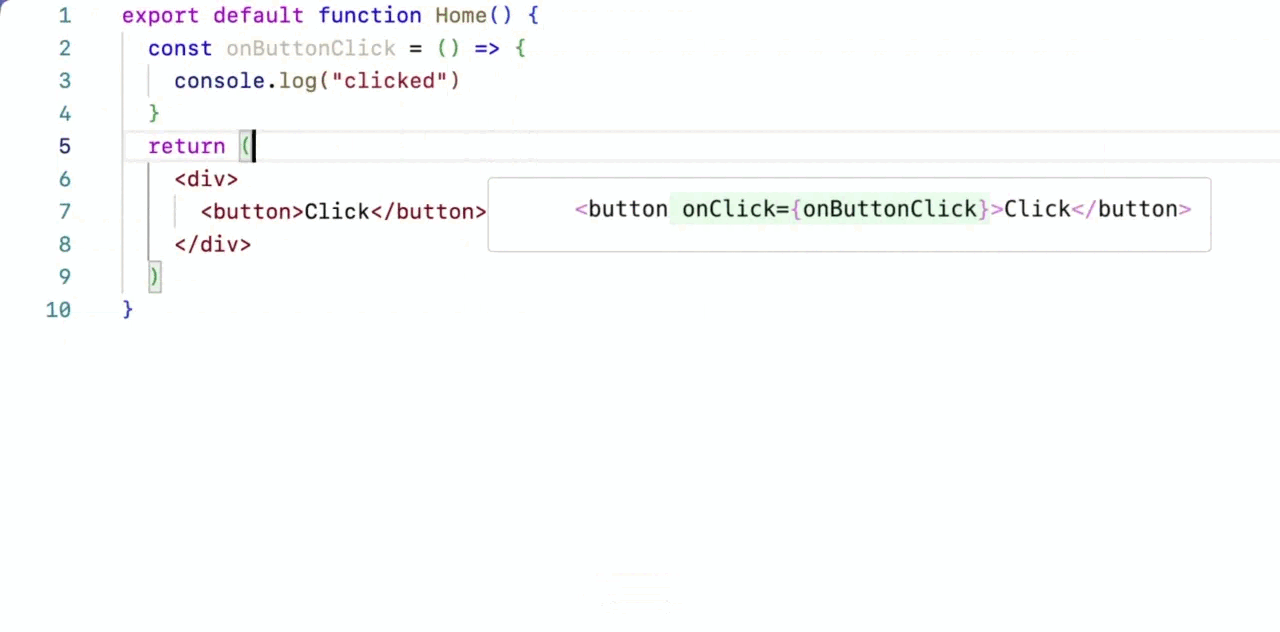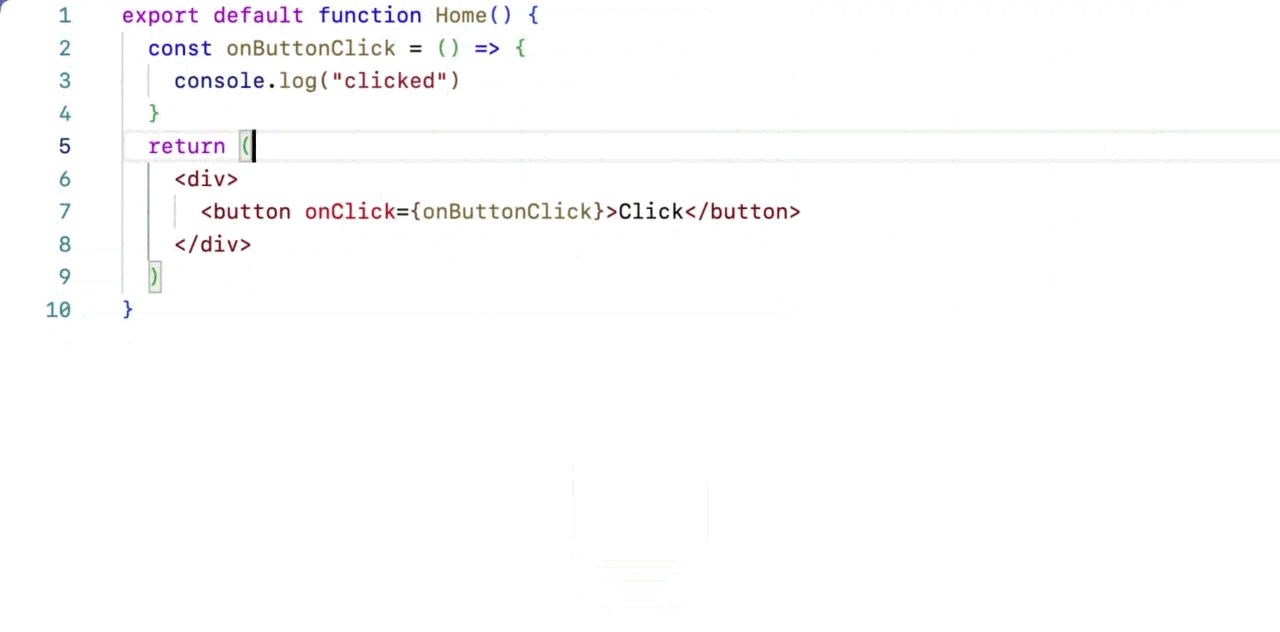
You see how AI continues to handle more and more coding tasks with increasing levels of complexity and abstraction.
We got the low-level of code completions…
Then we got higher-level action completions with Cursor and this Windsurf Supercomplete stuff.
Now we’re starting to have full-blown agents to handle much more advanced programming tasks.
And these agents will only continue to get better.
How long until they completely take over the entire coding process?
And then the entire software development life cycle?
You know, some people say the hardest part of software development is getting total clarity from the user on what they want.
They say coding is easy but other parts of the software dev process like this initial requirements stage is hard and AI won’t be able to do it.
But this is mostly cope.
Telling an AI exactly what you want is not all that different from telling a human what you want. It’s mostly a matter of avoiding ambiguity using context or asking for more specificity — with like more detailed prompts.
AI agents are rapidly improving and will be able to autonomously resolve this lack of clarity with multi-step prompting.
Now we’re seeing what tools like Windsurf and Cursor Composer can do.
So, how to get started with Windsurf?
Windsurf comes from the same people that made that free Codeium extension for VS Code, so you’ll get it at codeium.com
And there’s a pretty good free version, but it won’t give you all the unique features that really make this IDE stand out.
You only get a limited free trial at the agentic Cascade feature — you’ll have to upgrade to at least Pro to really make the most of it.

Before the Pro price was $10 per month for unlimited Cascade use, but developers used it so much that they had to set limits with a higher price and introduce a pay-as-you-go system.
Eventually coding is going to change forever as we know it. And software developers are only going to have to adapt.