
Yet another unbelievable open-source coding model just got unleashed into the world.
Imagine a model that’s just as intelligent as Claude Opus — but 13 times cheaper!
But no need for you to imagine anymore — because this is exactly what the new MiniMax M2.5 is:
- Unbelievably cheap — yet still incredibly smart
- Blazing fast
- Open-source with open weights
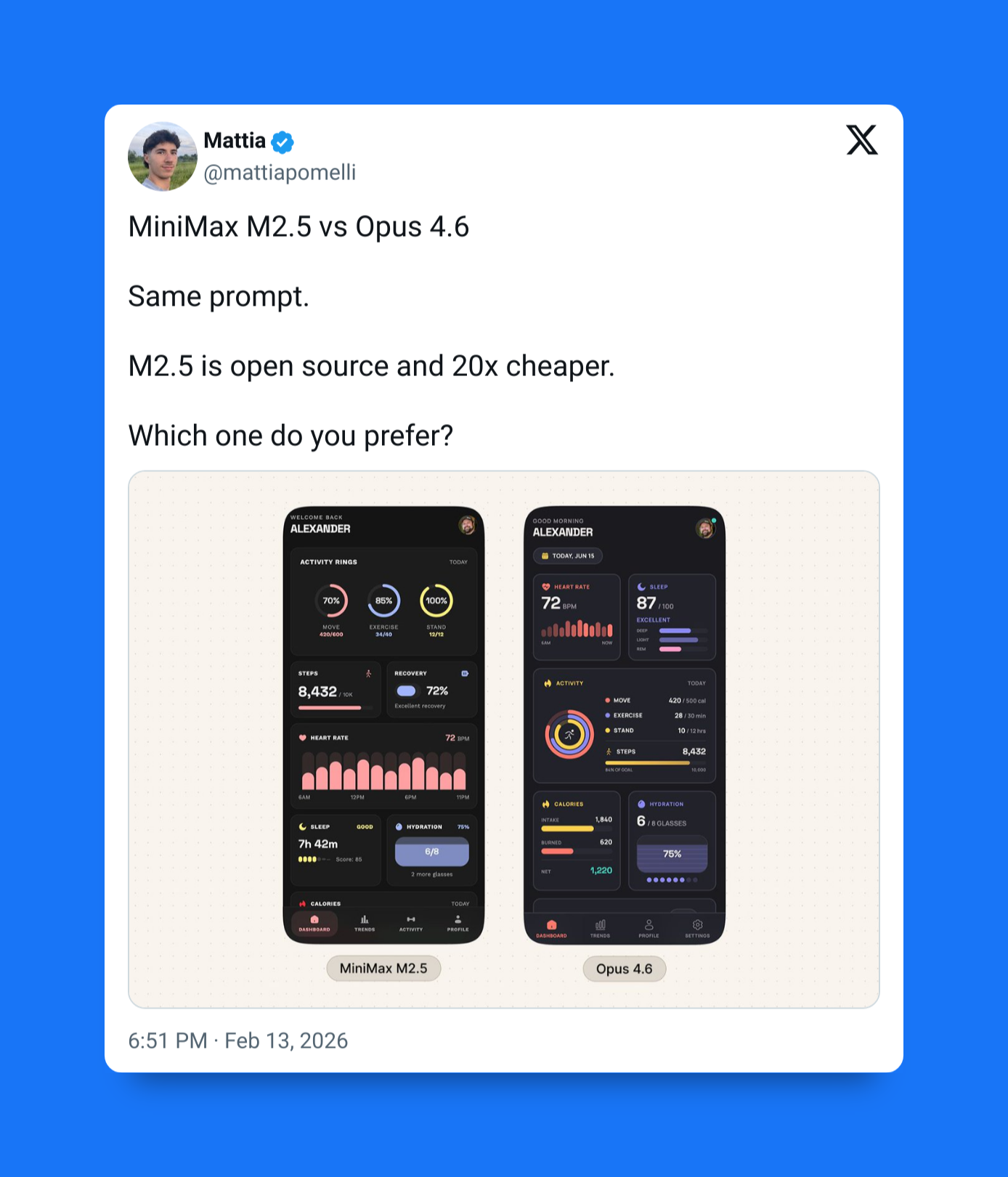
No wonder I’ve been seeing so many developers going crazy about it.
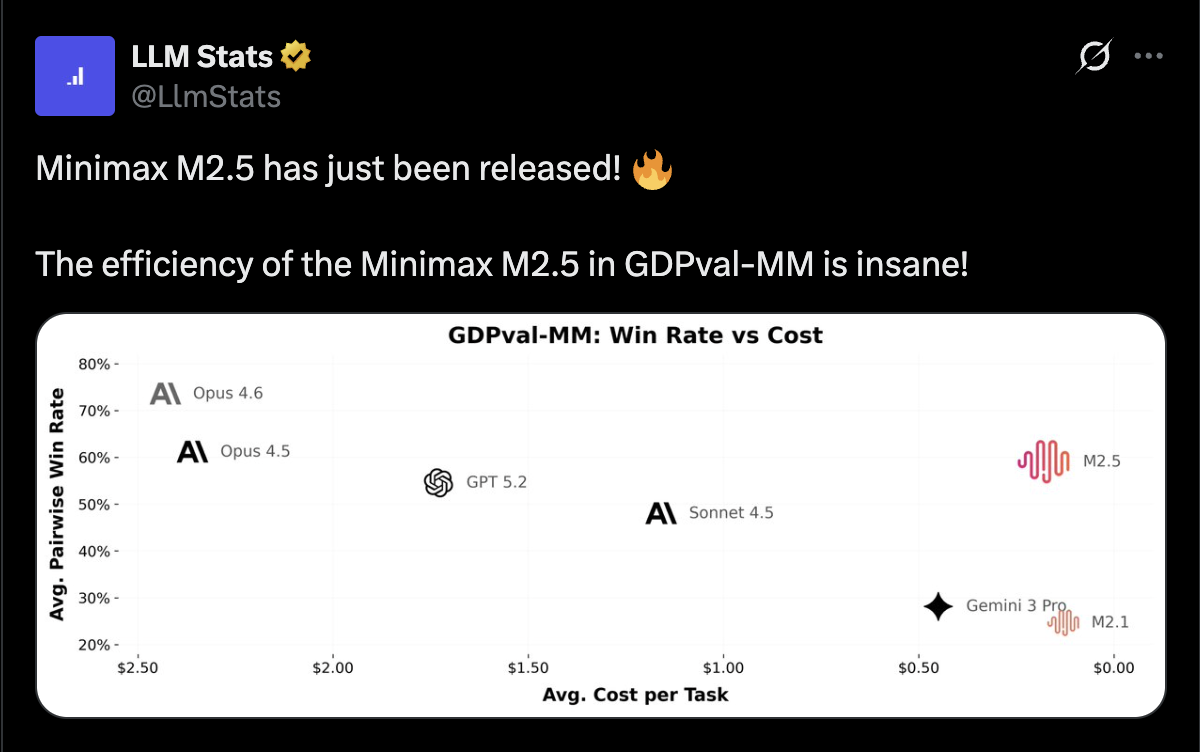
I’m seeing experiments showing that you can run complex agentic tasks continuously for as low as $1 for every hour of output.
This is going to be massive for all those our long, multi-step workflows where the models need to plan, browse, write code, revise outputs, and loop until something works.
Aggressive pricing
This is like the biggest reason for all the buzz right now:
- Performance in real coding and agent workflows comparable to Claude Opus–class models
- Roughly 13× cheaper in practical usage scenarios
- Cost low enough that you stop optimizing prompts purely to save money
This is going to make a real difference.
Most agent systems fail economically before they fail technically:
- In development: repeated tool calls and retries multiply costs quickly.
- In production: cost add up fast as a growing list of users repeatedly try out multiple AI-powered features
M2.5’s pricing is designed to remove that constraint.
Standard pricing:
- $0.30 per 1M input tokens
- $1.20 per 1M output tokens
At rates like these, running long reasoning loops or persistent background agents becomes financially realistic for much larger workloads.
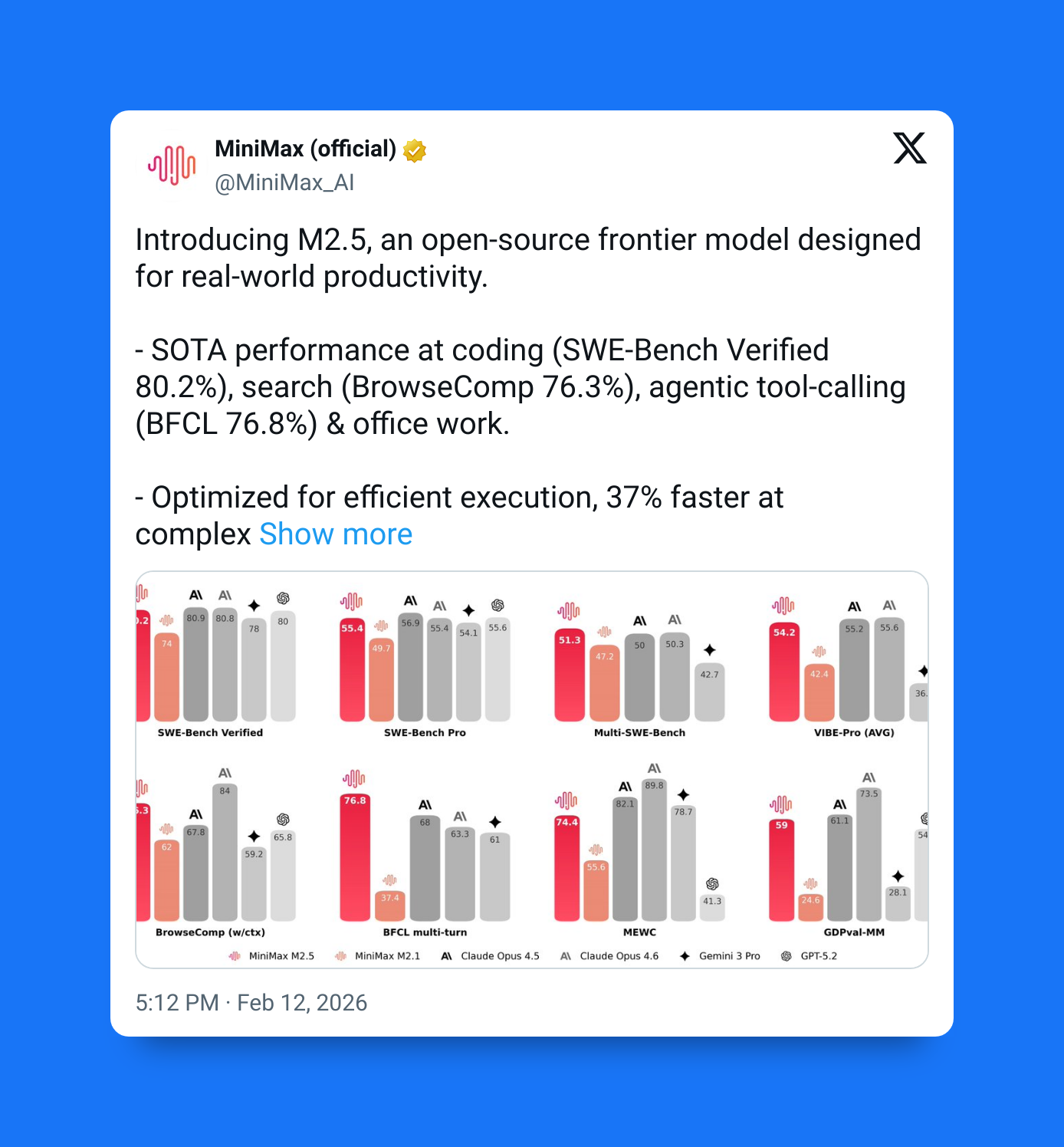
The benchmark that made engineers pay attention
- 80.2% on SWE-Bench Verified
This is it.
SWE-Bench Verified is widely considered one of the more meaningful coding benchmarks because it measures whether a model can actually resolve real GitHub issues under constrained evaluation conditions.
A high score here signals something specific:
- Strong code understanding
- Ability to follow multi-step debugging processes
- Reliability in structured environments
In other words, it suggests the model can do more than generate code — it can fix existing systems.
Ridiculously fast
Raw intelligence is only part of agent performance. Speed determines whether iteration is usable.
M2.5’s high-speed variant runs at approximately:
- 100 tokens per second
That level of throughput changes how agents behave in practice:
- Faster plan → execute → verify cycles
- Less waiting between iterations
- Higher tolerance for multi-pass refinement
- Better human experience when supervising agents
Many agent workflows involve dozens of internal steps. When each step is fast, experimentation becomes normal instead of frustrating.
Open weights: control instead of dependency
Another major part of the story is that M2.5 is not just an API product.
MiniMax released:
- Open weights
- A permissive modified-MIT style license
- Support for local deployment stacks
This matters for companies building internal tooling because it allows:
- Local inference for sensitive data
- Predictable costs at scale
- Custom infrastructure integration
- Reduced vendor lock-in
The combination of strong performance and deployability makes M2.5 particularly attractive for engineering teams building long-lived internal agents.