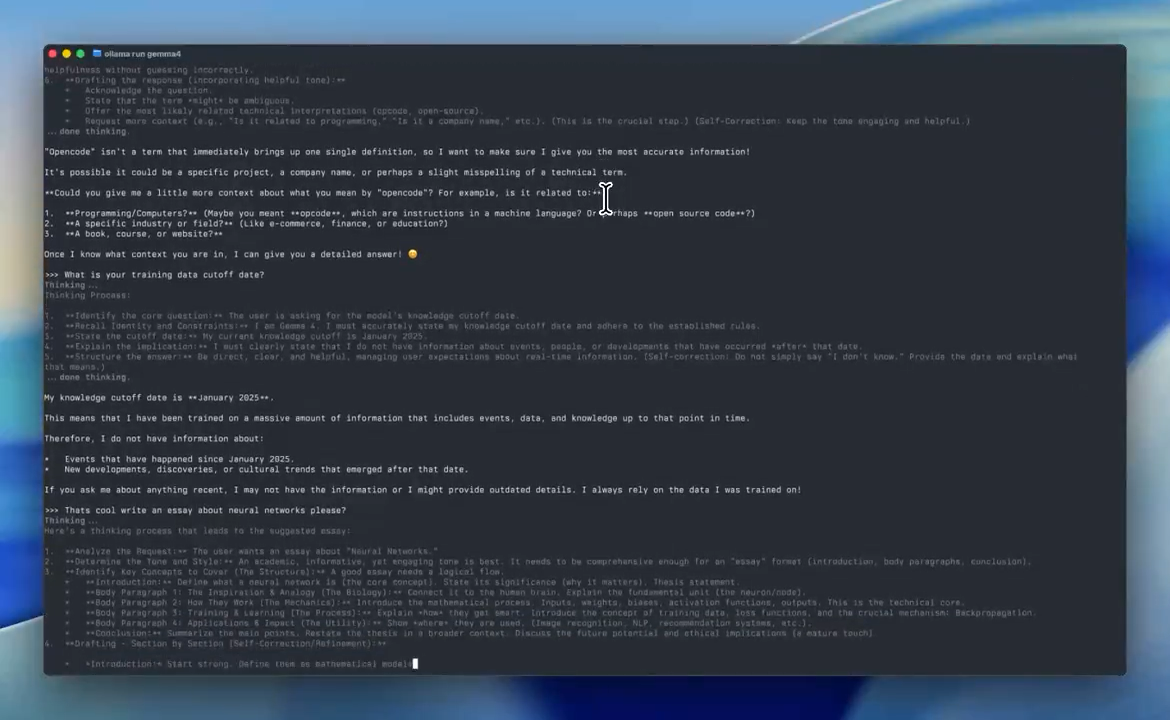
This is absolutely insane.
Google’s new Gemma 4 open-source model just completely changed the AI model landscape forever.
AI just became FREE.
You can literally connect this to Claude Code with something like Ollama and never spend money on API keys ever again.
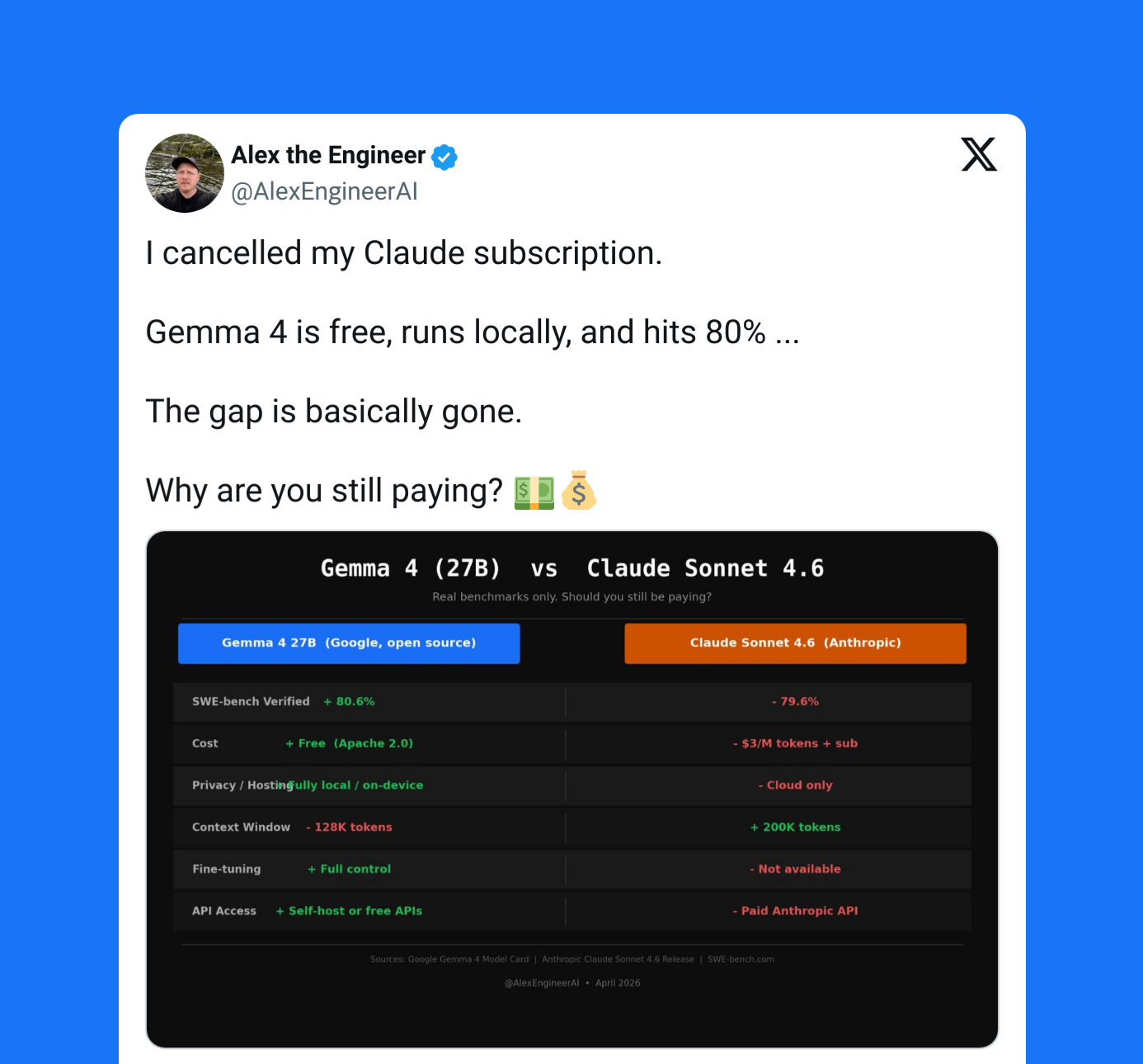
An open-source model that’s actually lean and intelligent? That isn’t just a glorified PR move?
That devs can actually use in production with amazing results? Without spending a dime once they download the model?
Just WOW.
Wild comparison: ChatGPT 5 (left) vs Gemma 4 (right):
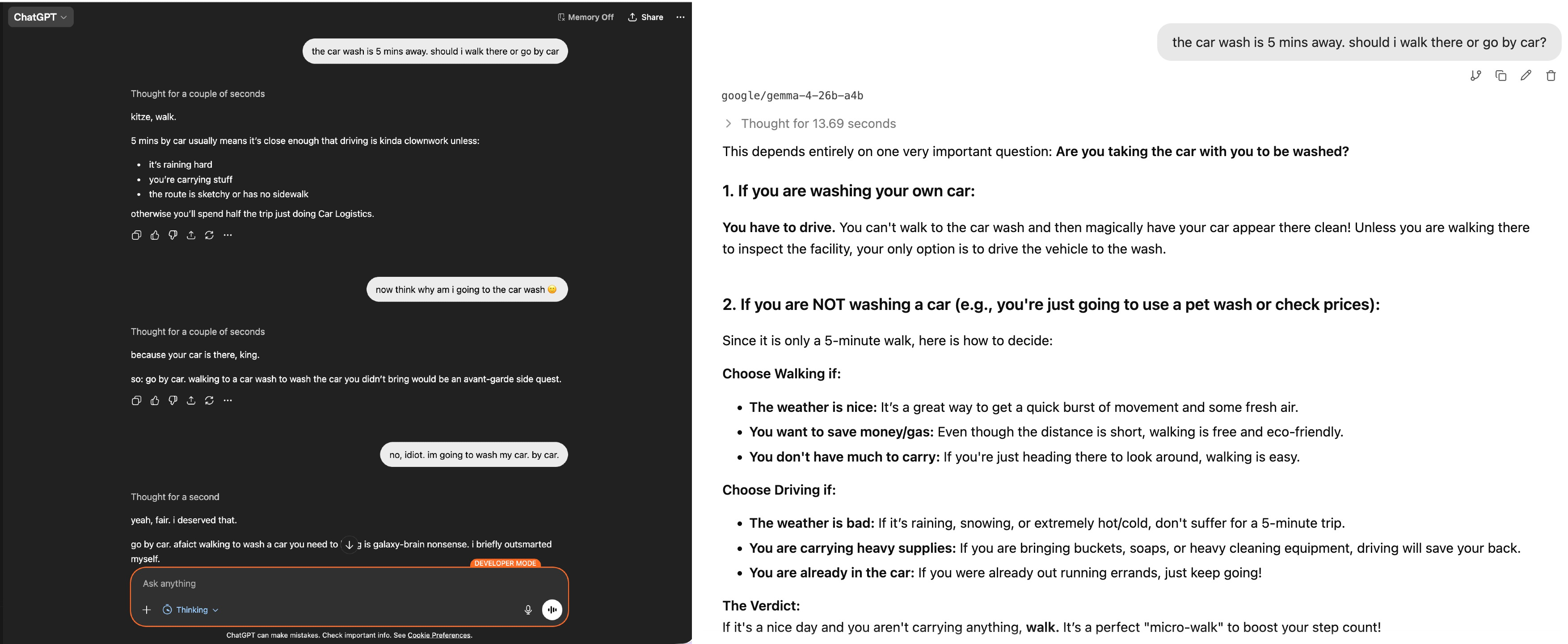
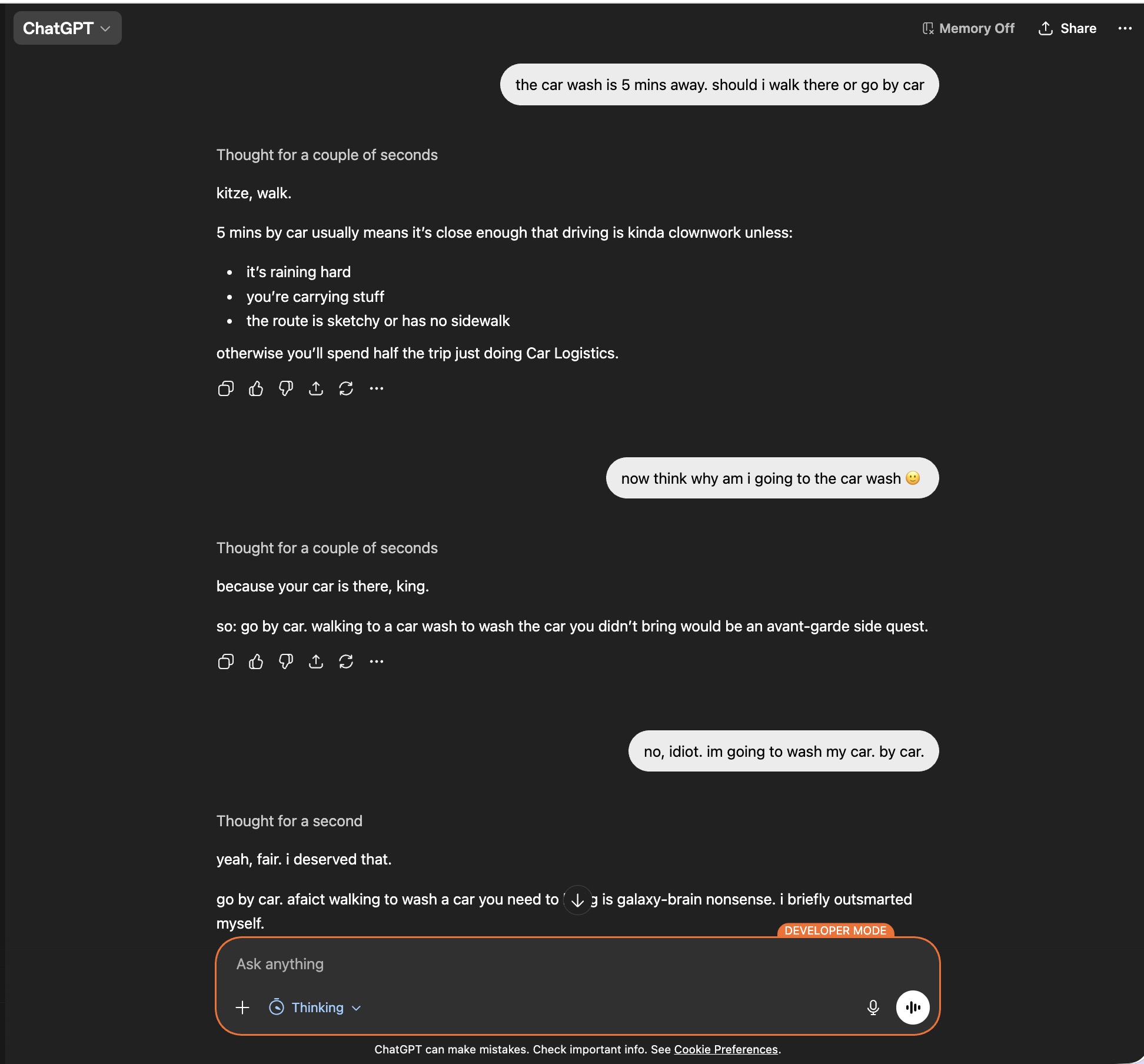
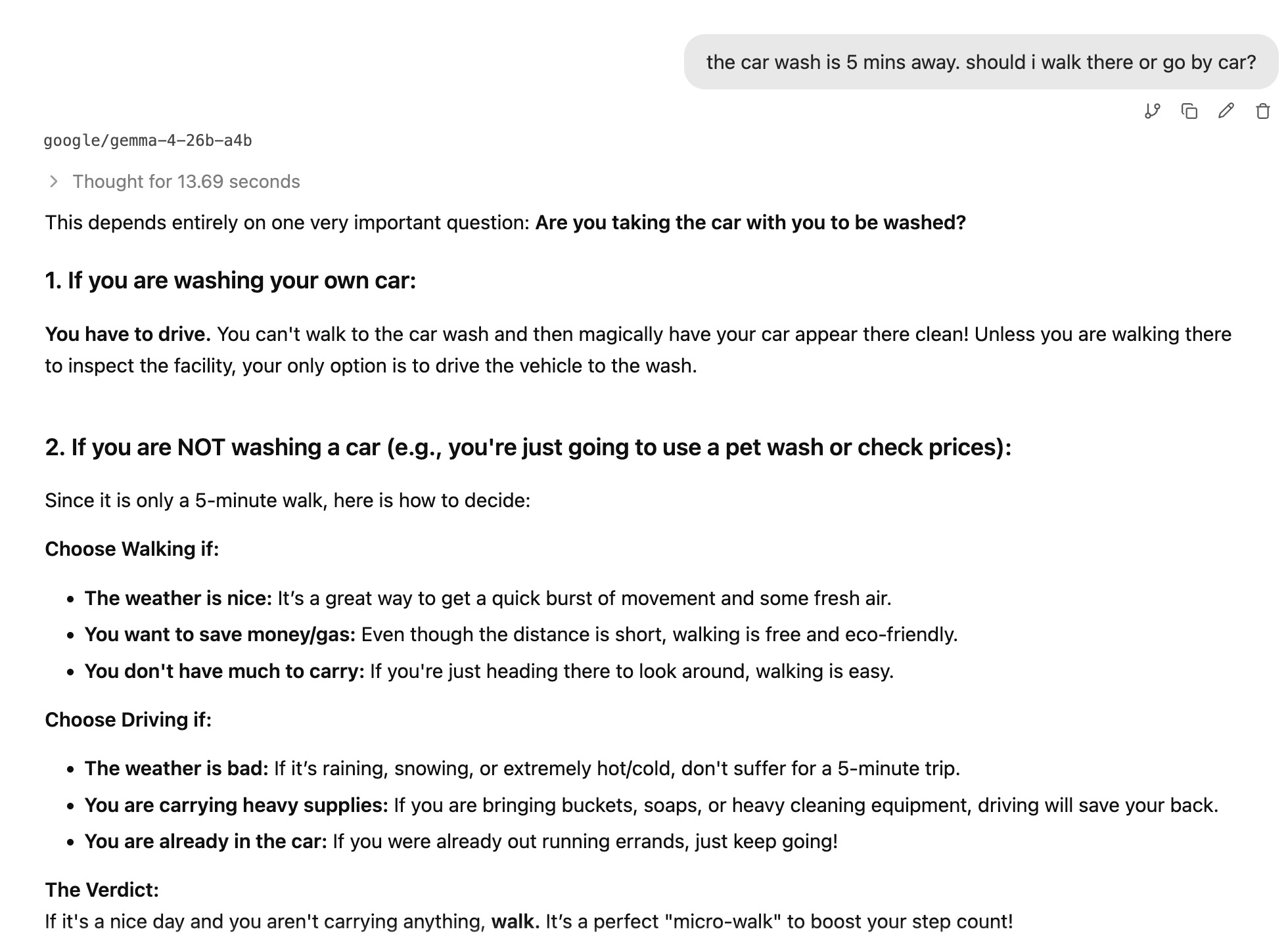
The efficiency is incredible — you don’t need to trade in your two arms and legs to buy enough RAM to run it.
It’s literally tiny enough to run locally on your phone:
Gemma 4 running locally on a phone with zero internet access:
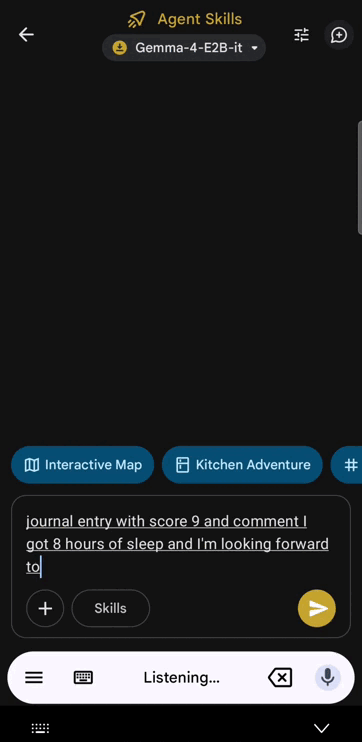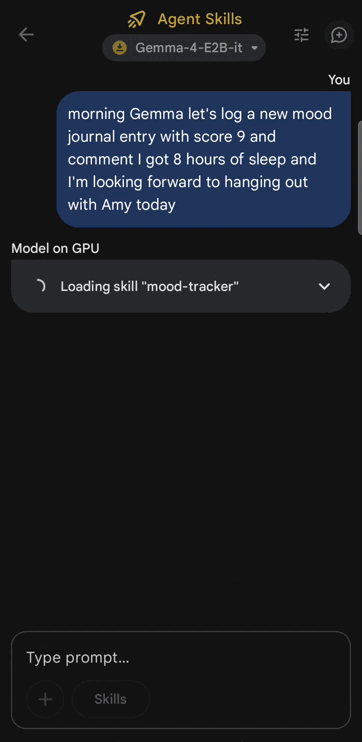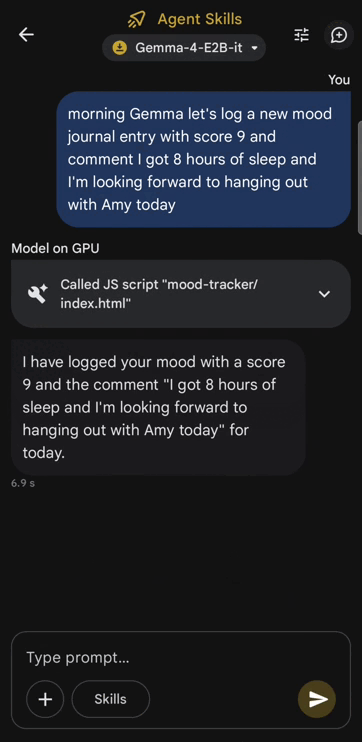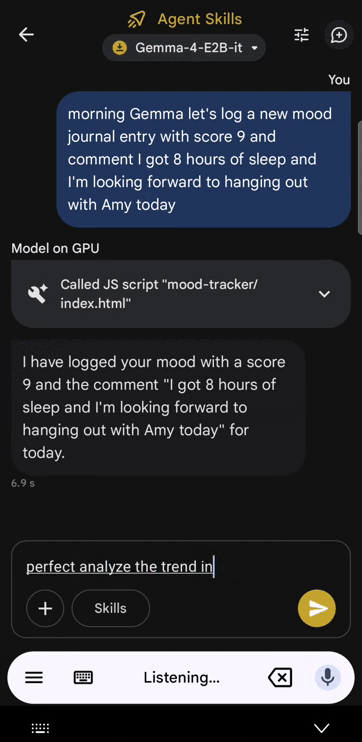
Comes in four distinct models for every possible use case:
- E2B — 2.3B effective (~5.1B w/ embeddings) — ~1.7GB — ~1.5–2GB RAM
- E4B — 4.5B effective (~8B w/ embeddings) — ~3.2GB — ~3–4GB RAM
- 26B A4B — 26B total (4B active) — ~8–12GB RAM
- 31B Dense — 31B — ~17GB — ~16–20GB RAM
1. Destroying models 20x its size

Google build Gemma 4 with a huge huge focus on intelligence-per-parameter.
And the numbers are striking:
- The 31B dense model ranked #3 globally on the Arena AI leaderboard for open models
- It beats models 10–20× larger
- The 26B A4B model ranked #6
- Smaller models perform far above their parameter counts
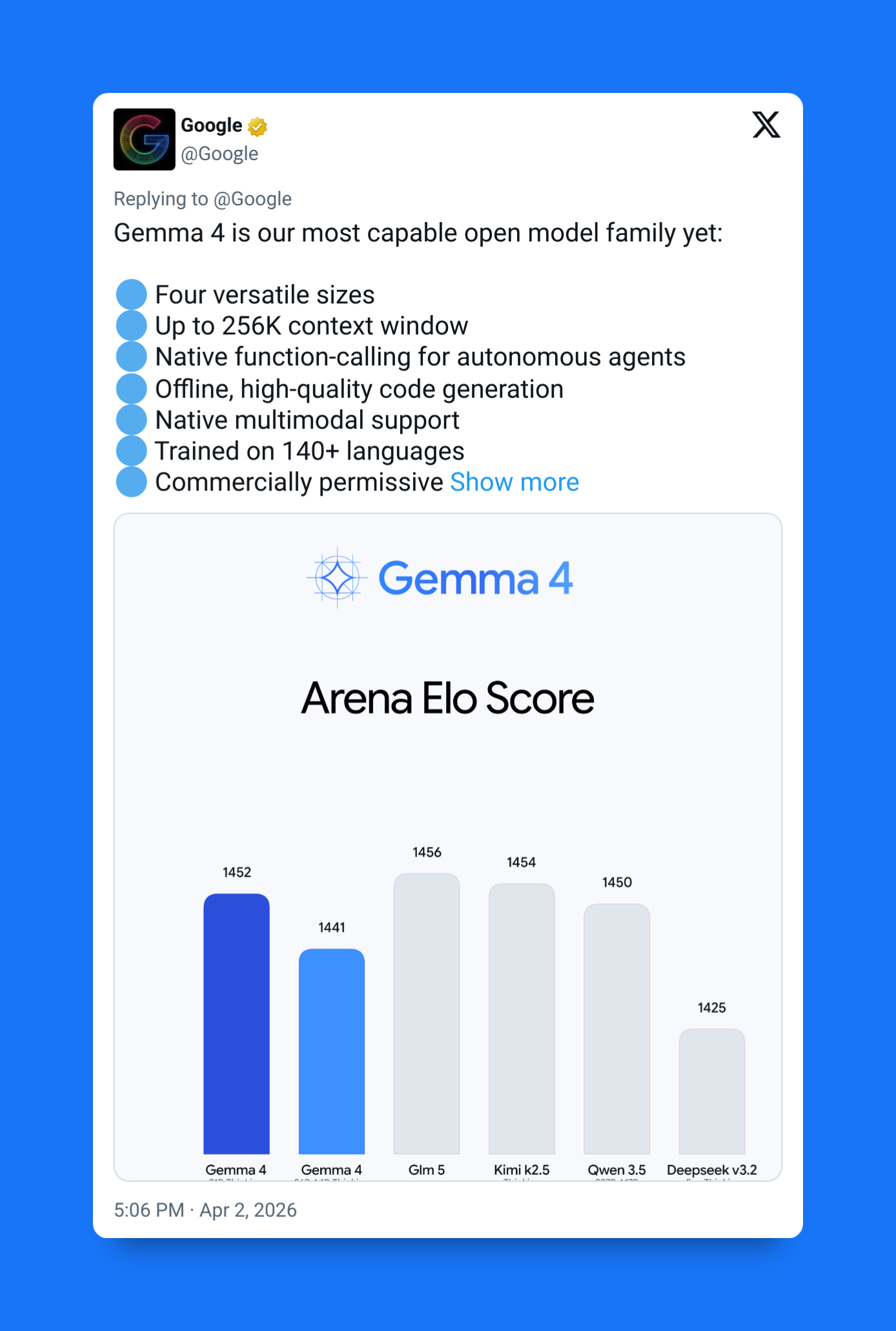
This isn’t brute-force scaling — like OpenAI was doing with the GPT models. It’s architectural efficiency.
The biggest reason: the new Effective (E) architecture.
The E2B and E4B models use Per-Layer Embeddings (PLE) — a new state-of-the-art technique designed to make smaller models behave like much deeper ones.
The result:
- E2B physically fits under ~2GB RAM (quantized))
- Performs like a 5B–8B class model
- Supports multimodality
- Supports reasoning
- Supports long context
These are not “small toy models.”
They’re lightweight models with heavyweight intelligence.
More intelligence.
Less memory.
Better, easier deployment.
It’s a real game-changer for open models.
2. Native multimodality (vision + audio)
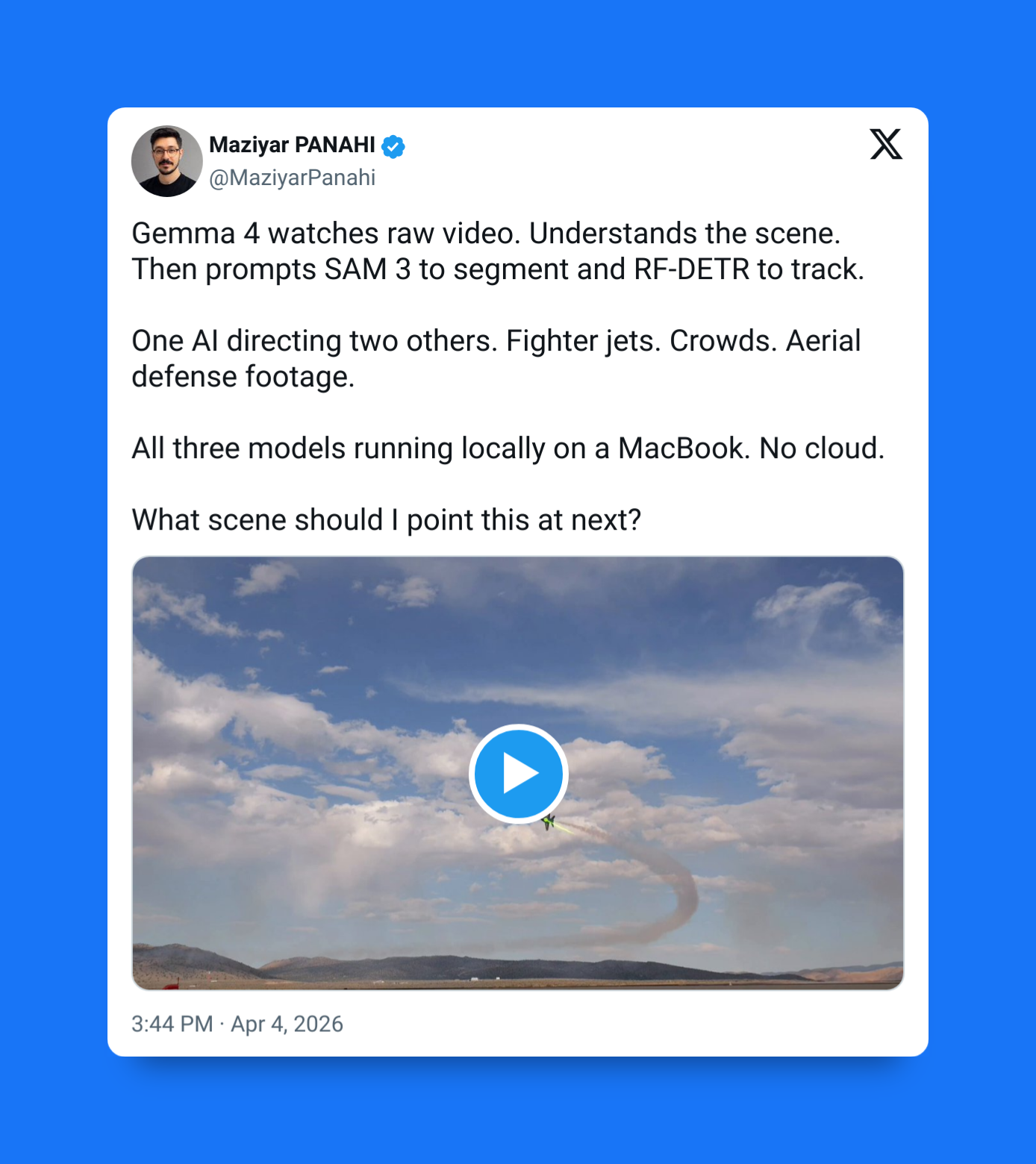
Gemma 4 is fully multimodal, and for the Gemma flagship line this is the most complete implementation yet.
Vision (all models)
- Images supported natively
- Video supported up to 60 seconds
- Strong at OCR
- Strong at chart understanding
- Strong at document parsing
- Structured output for visual tasks
This isn’t just “describe the image.”
It’s built for real document and UI workflows.
Audio (E2B / E4B)
The small edge models also support native audio:
- Speech recognition
- Speech translation
- Multilingual audio input
- ~30 second audio window
This is extremely rare for models this small.
You can run speech + reasoning + multimodal locally.
Variable resolution vision
Gemma 4 introduces token-budgeted vision.
You choose how detailed the image representation should be:
- 70 tokens — fast
- 140 tokens
- 280 tokens
- 560 tokens
- 1,120 tokens — high detail
Tradeoff:
- fewer tokens → faster inference
- more tokens → better visual precision
This makes Gemma 4 practical for:
- OCR pipelines
- video frame processing
- UI automation
- document AI
- mobile deployments
It’s a very pragmatic design.
3. Built for the brave new agentic era
Out of the box:
Function calling
- Native tool triggering
- Structured JSON outputs
- Reliable parameter filling
- Multi-step tool reasoning
This enables:
- search agents
- calendar agents
- coding assistants
- workflow automation
No hacks required.
Thinking mode
Gemma 4 supports a configurable reasoning mode.
When enabled, the model:
- works step-by-step
- reasons before answering
- improves tool-use accuracy
- improves coding reliability
This mirrors the new generation of reasoning models — but in an open model.
Long context
- 256K context (larger models)
- 128K context (E models)
That’s:
- entire books
- large codebases
- long conversations
- multi-tool agent memory
Gemma 4 is built for stateful agents, not just prompts.
4. Open sovereignty: real open-source
Gemma 4 moves to the Apache 2.0 license.
That changes everything.
Developers can:
- modify the model
- fine-tune freely
- redistribute
- commercialize
- embed in products
- ship on-device
- run privately
No royalties.
No restrictive acceptable-use clauses.
No platform lock-in.
This puts Gemma 4 directly against:
- Llama
- Qwen
- other open-weight ecosystems
And signals Google taking open models really seriously.
This will change everything
Put it all together:
- Extremely high intelligence-per-parameter
- Efficient “Effective” models under 2GB
- Multimodal across the entire family
- Audio on small edge models
- Agent-ready architecture
- 256K context
- Apache 2.0 licensing
- Four deployment sizes
This is not just a model release.
It’s Google building a complete open AI stack:
Small.
Powerful.
Local.
Agentic.
Multimodal.
Gemma 4 isn’t trying to be the biggest model.
But it’s certainly trying to be the most powerful, most efficient, most useful open one.