
Wow I’ve never seen Sonnet do something like this before. This is huge.
You absolutely cannot ignore this.
I don’t even need to compare it to GPT or Gemini or whatever.
Claude Sonnet is actually no longer trying to be a nice little tradeoff between intelligence and cost.
This new Claude Sonnet is here to be a MASSIVE CHALLENGER to its big brother Claude Opus.
And from the numbers I’m seeing, it has made dangerous progress toward achieving that with this new 4.6 update.
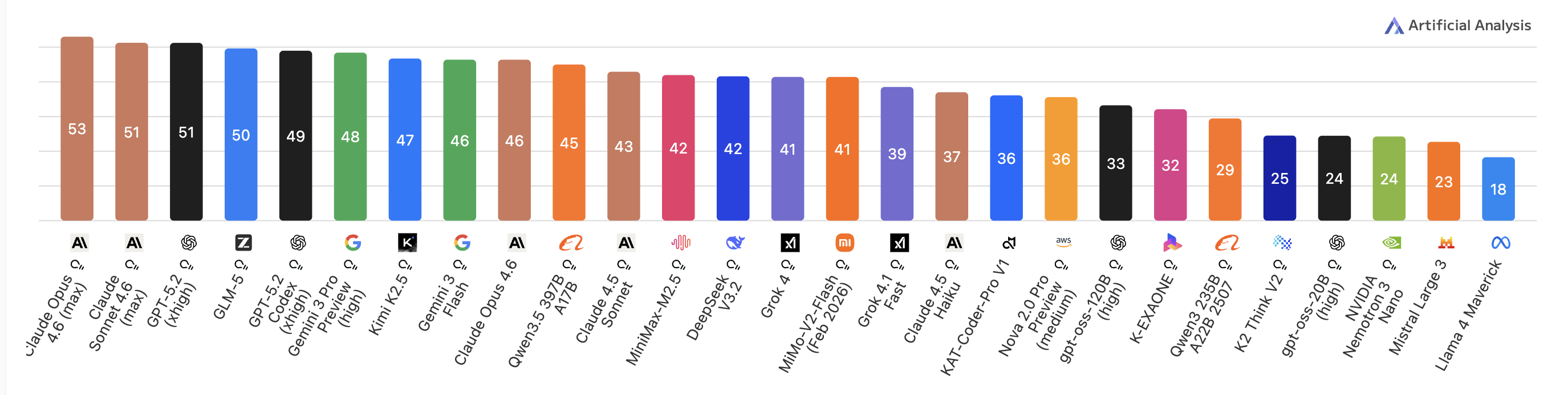
It decimated the previous version of Claude Opus (4.5) in basically every metric — and was incredibly close to the current Opus version — and even beat this latest Opus in notable areas.
Literally 2nd position in the biggest AI benchmarks out there — and guess the one model that stopped it from gaining top spot?
It’s gotten so much better at automating actions on your computer now (Computer Use):

1 MILLION token context — trust me this is not a model you want to mess around with.
With Sonnet 4.6, Claude will handle all your real-world, production AI workloads — especially coding and tool use — without the higher cost of Opus.
1. Essential coding upgrade — that we will all feel
Sonnet 4.6 scored 79.6% on SWE-bench Verified, extremely close to Opus 4.6’s ~80.8%, showing near-flagship coding performance at lower cost.
And not just benchmarks. Sonnet 4.6 is here to work with us in real workflows:
- Understanding large repos
- Editing across multiple files
- Avoiding unnecessary rewrites
- Following existing structure instead of “overengineering”
In Anthropic’s own testing, developers preferred Sonnet 4.6 over Sonnet 4.5 about 70% of the time in Claude Code, citing better context reading and less duplication/overengineering.

2. Unbelievable Computer Use gains
Anthropic has been massively pushing Computer Use lately: the AI models controlling out software like we would to carry out complex actions for us — clicking, typing, navigating interfaces along the way.
With 4.6, that capability improved significantly.
Sonnet 4.6 achieved 72.5% on OSWorld-Verified, dramatically up from Sonnet 4.5’s ~61.4% and nearly matching Opus 4.6’s ~72.7%, which demonstrates near-parity in practical interface interaction tasks.
Sonnet 4.6 now performs nearly on par with Opus in Computer Use.
That’s a big deal because computer-use tasks are messy. They require:
- Reading dynamic UI elements
- Recovering from small mistakes
- Planning multi-step actions
It’s not perfect, but it’s much closer to “practical assistant” than previous versions.
3. 1M is serious business
The new 1 million token context window means you can easily:
- Load an entire workspace spanning multiple codebases
- Drop in several multiple long contracts
- Analyze huge research dumps
- Work across extended conversation history
More importantly, Anthropic emphasizes that 4.6 isn’t just ingesting that volume — it’s designed to reason across it.
For anyone doing knowledge-heavy work, that’s where things get interesting.
4. Built agentic and terminal workflows — notable upgrades
Sonnet 4.6 posted 59.1% on Terminal-Bench 2.0, a notable improvement over Sonnet 4.5’s ~51.0% and closer to Opus 4.6’s ~62.7%, underscoring progress in complex, multi-step coding tasks.
Sonnet 4.6 feels very optimized for agents — the kind that:
- Plan
- Call tools
- Execute steps
- Reflect
- Iterate
Sonnet 4.6 scored 91.7% (retail) and 97.9% (telecom) on t²-bench agentic tool use, which is a clear improvement over Sonnet 4.5’s 86.2 % retail and essentially on par with Opus 4.6’s 91.9 % retail and 99.3 % telecom results.
Benchmarks around tool use (like t²-bench) suggest strong reliability when interacting with structured tools and APIs.
If you’re building workflows that involve repeated tool calls and feedback loops, cost-to-performance matters. And this is where Sonnet 4.6 seems carefully positioned.
5. Safety and prompt injection resistance
When models start browsing or using tools, prompt injection becomes a serious concern.
Sonnet 4.6 significantly improves resistance to malicious or hidden instructions compared to 4.5, performing similarly to Opus 4.6 in safety evaluations.
In other words: it’s better at ignoring sketchy instructions embedded in web pages or documents.
That matters a lot for autonomous or semi-autonomous systems.
6. Pricing stays the same
This is one the biggest deals in this release.
Sonnet 4.6 is far far better than both Sonnet 4.5, yet the pricing remains the same.
- $3 per million input tokens
- $15 per million output tokens
Sending the clear message:
Opus-level reliability in many workflows — without Opus-level cost.
When should you use it?
Choose Sonnet 4.6 if you want:
- A daily-driver model for coding
- A strong agent backbone
- Large context handling
- Reliable tool usage
- Production deployment without premium-tier costs
Choose Opus 4.6 if:
- The reasoning task is extremely complex
- Precision is mission-critical
- You’re doing heavy multi-agent orchestration
For most teams, Sonnet 4.6 is likely to become the default.
Anthropic seems to be collapsing the gap between “mid-tier” and “frontier.”
Instead of forcing users to upgrade to Opus for serious work, they’re making Sonnet strong enough to handle most of it.
If 4.5 felt like a capable assistant, then 4.6 feels more like a dependable coworker — especially for developers.
And that might be the real story here.