
Woah this is incredible.
Anthropic just released the new Claude Opus 4.5 — and it’s better than every other coding model at basically everything.
Just look at the insane difference between Opus 4.5 and Sonnet 4.5 in solving this complex puzzle game:
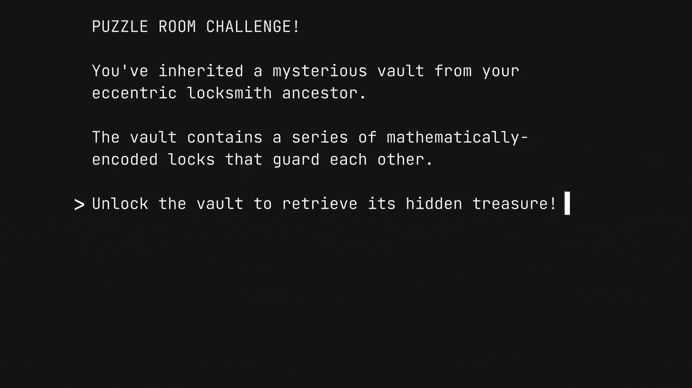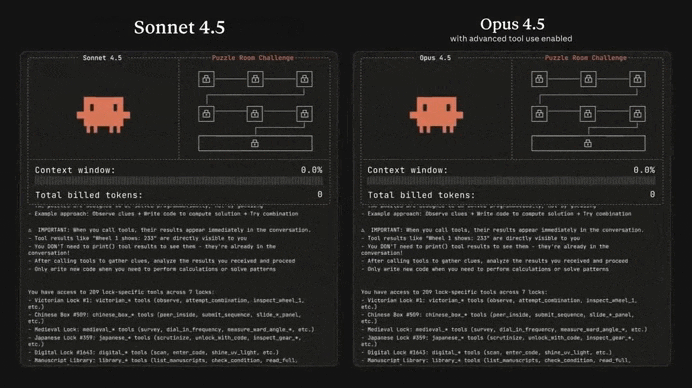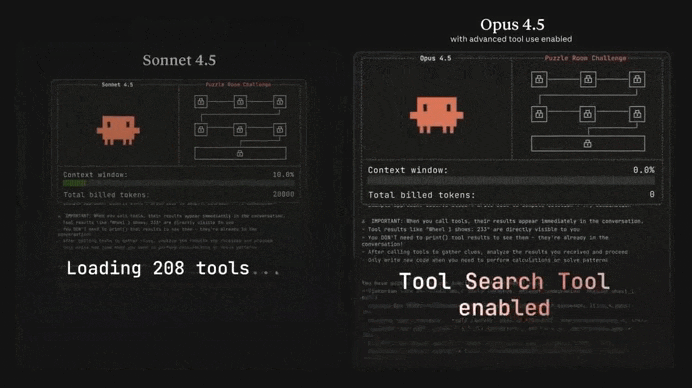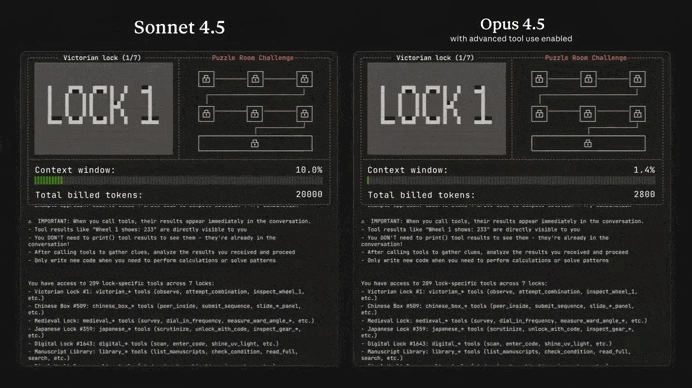
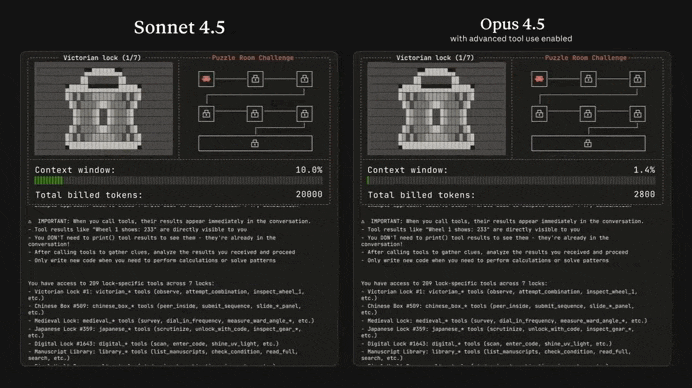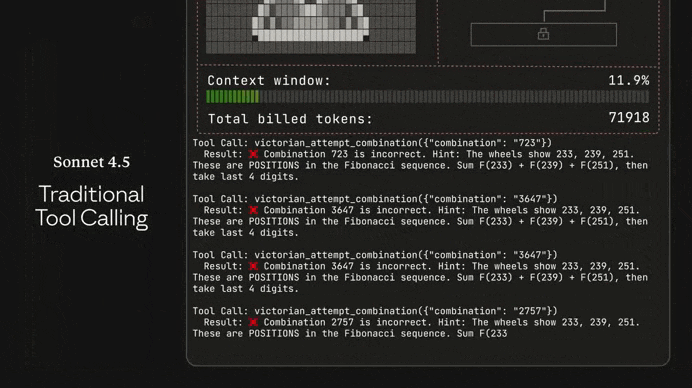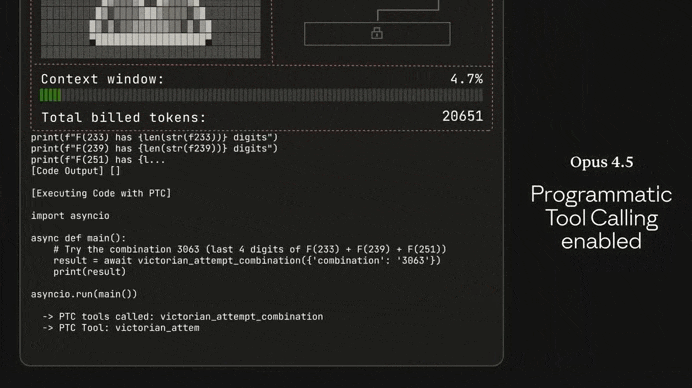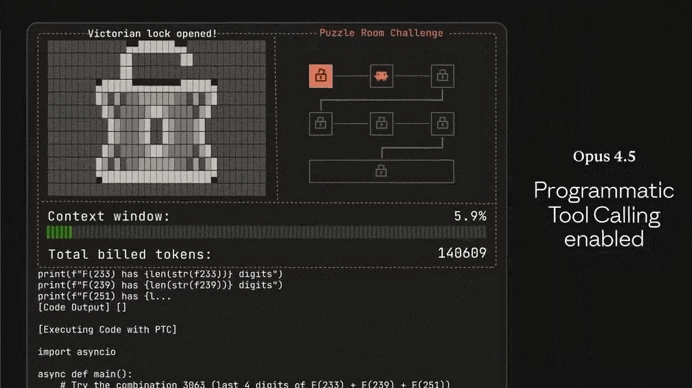
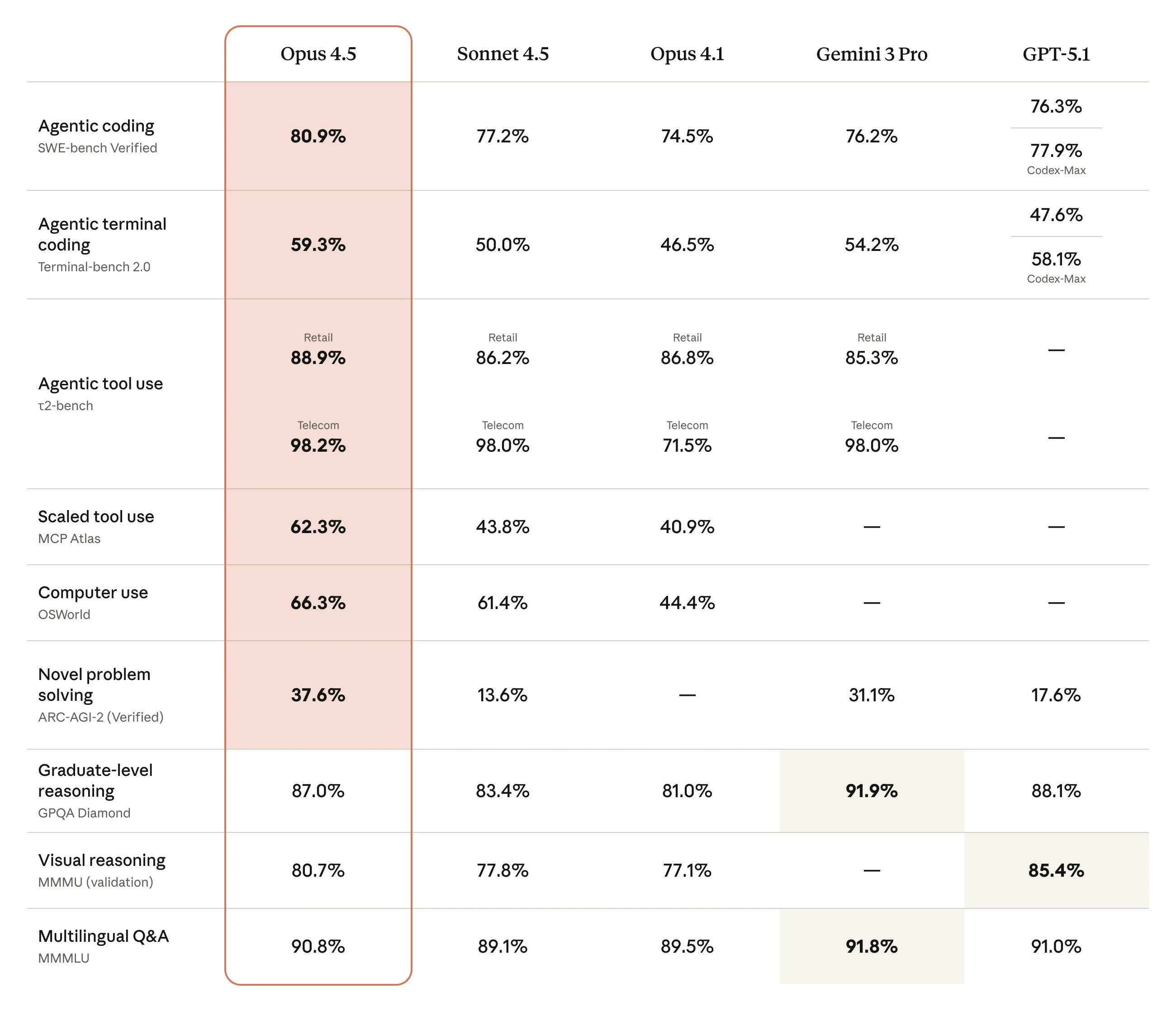
Many devs online have been calling it the greatest coding model ever — not hard to believe when you see how it stacks up to the other models:
It even beats Gemini 3 Pro that just came out like a week ago:
This is a model built from the ground up to be an agentic software engineer: fixing bugs, refactoring large codebases, navigating unfamiliar repos, and wiring everything together with tools and terminals.
Opus 4.5 isn’t just competitive — it’s designed to be the thing you reach for when failure is expensive.
80% on the SWE-bench verified benchmark is the highest ever any model has ever gotten.
And this SWE-bench Verified is a benchmark where models must actually apply patches that pass tests in real GitHub repos. It’s the sort of test where you’re not answering quiz questions — you’re actually modifying real-world Python projects and passing every single written test in the codebase.
Anthropic also ran it on their two-hour engineering hiring exam and reported that Opus 4.5, under realistic constraints, scored higher than any human candidate they’ve evaluated — though with the important caveat that it was allowed multiple runs and they picked the best.
You can see that Opus 4.5 is optimized for “here’s a repo, make it work,” not just “explain what a binary search tree is.”
This is advanced software engineering for messy real-world tasks — far more than just “build a todo list app”.
The effort knob: turning up (or down) the brainpower
The most interesting feature for coders is the effort parameter — exclusive to Opus 4.5 for now.
Instead of swapping between different models, you tell Opus 4.5 how hard to think for this request:
- Low effort – quick, cheap answers. Great for small edits, simple scripts, regexes, or “explain this function” type questions.
- Medium effort – the sweet spot for most coding tasks. Anthropic has shown that at medium effort, Opus 4.5 can match the best coding results of Claude Sonnet 4.5 while using fewer tokens, i.e., similar quality for less cost.
- High effort – full-brain mode for gnarly debugging, tricky refactors, architecture changes, or multi-file feature work.
Crucially, effort applies not just to the visible text but also to tool use and hidden “thinking.” That means you can reserve high effort for tickets where getting it wrong is painful, and run low/medium as your default autopilot in an IDE or CI workflow.
Built for end-to-end dev workflows
For programmers, the real value shows up when you plug Opus 4.5 into an environment where it can actually do things:
- Repo navigation & refactors – With a huge context window, Opus 4.5 can load multiple files, trace a bug across layers, propose refactors, and update tests in one go instead of treating every file as an isolated puzzle.
- Tool and terminal use – When connected to tools (compilers, linters, test runners, deployment scripts), it can follow a “tight loop”: propose change → run tests → read failures → iterate. This is exactly what you’d expect from a junior/mid engineer sitting at your repo.
- Long-horizon tasks – It’s better at keeping track of multi-step plans: e.g., “migrate this service from Express to FastAPI,” or “split this monolith into three services and update the client.”
In practice, this makes Opus 4.5 a strong candidate for being the engine behind AI pair programmers, autonomous PR bots, and coding copilots that don’t fall apart once the task stops being toy-sized.
Where you’ll actually use it
You don’t have to adopt a new toolchain to touch Opus 4.5. It’s being integrated into:
- Cloud coding assistants and IDE plugins (e.g., via GitHub Copilot and other dev tools).
- Enterprise stacks on AWS, Azure, and Google Cloud, where teams can wire it into internal repos, CI systems, and ticket queues.
What Opus 4.5 really changes
If earlier Claude and GPT-style models were like helpful interns, Opus 4.5 is trying to be the mid-level engineer you can trust with ugly, ambiguous problems:
- It understands messy legacy code instead of just clean examples.
- It can stay on-task across long debugging or refactor sessions.
- You can decide, per task, how much “brainpower” you’re willing to spend.
We’re still early in the era of AI dev agents, but Opus 4.5 is one of the clearest signals so far: the future of coding isn’t just autocomplete — it’s handing larger and larger chunks of the software lifecycle to models that can reason, iterate, and ship.