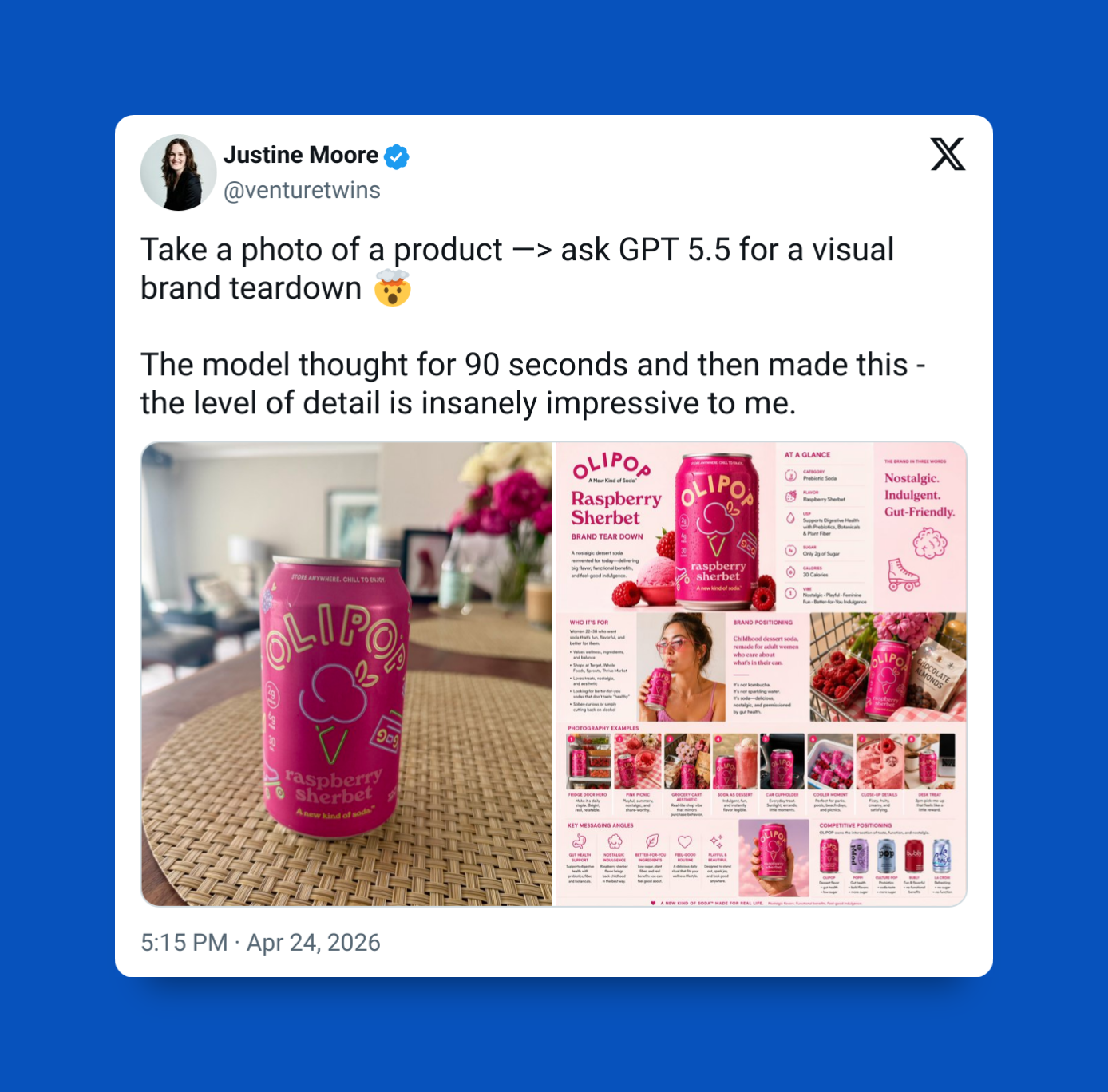
This was such a massive upgrade.
OpenAI saw all the craze going on with Opus 4.7 — so of course they had to quickly release a new model to steal back the spotlight.
And these are some pretty incredible upgrades over GPT-5.4 we got here — no developer should ignore this.

Like now it’s gotten sooo much better at processing extremely long context — more than 50% increase for very large inputs — something that will be very useful in development, for those humongous, intricately connected codebases.
GPT-5.5 doesn’t just extend context to 1 million tokens—it stays sharper inside it, improving Graphwalks BFS accuracy from 92.1% to 94.8% at 0–128K tokens and from 48.3% to 73.7% at 256K tokens.
It even comes with a new overpowered thinking mode and a new Pro variant — to build the most complicated features, and deal with the hardest bugs known to man.
1. Massive upgrades in long-context reliability
Many models advertise huge context windows. Few stay accurate when that context becomes truly massive.
GPT-5.5 ships with a 1 million token context window and a 200,000 token output limit — but the real story is measurable reliability at extreme scale.
On Graphwalks BFS, a benchmark that tests whether the model can follow chains of logic scattered across very large documents, GPT-5.5 shows major gains over GPT-5.4 as context size increases:
- At 0–128K tokens, GPT-5.5 scored 94.8%, up from 92.1% for GPT-5.4 (+2.7 points)
- At 256K tokens, GPT-5.5 scored 73.7%, up from 48.3% (+25.4 points)
- At the full 1 million token context, GPT-5.5 scored 45.4%, up from 21.4% (+24.0 points)
Those numbers matter because most models degrade sharply as context expands.
GPT-5.5 appears significantly better at retaining signal, tracing relationships, and reasoning across huge inputs.
For us developers that means stronger performance across:
- large monorepos
- architecture documentation
- multi-service dependency maps
- long debugging sessions
- logs, tickets, specs, and tests in one thread
- research across many files simultaneously
Instead of splitting work into small prompt chunks, teams can increasingly provide broader system context and let the model reason globally.
2. Incredible agentic coding and terminal use improvements
GPT-5.5 is heavy optimized for autonomous coding, tool use, debugging, and multi-step execution.
On Terminal-Bench 2.0, GPT-5.5 reportedly scored 82.7% compared with:
- GPT-5.4 at 75.1%
- Claude Opus 4.7 at 69.4%
- Gemini 3.1 Pro at 68.5%
That is a 7.6-point jump over GPT-5.4.
And this will reflect in how we developers actually work:
- inspect files
- run commands
- read errors
- patch code
- rerun tests
- iterate until fixed
On SWE-Bench Pro (Public), GPT-5.5 scored 58.6%, versus 57.7% for GPT-5.4 and 54.2% for Gemini 3.1 Pro.
3. Overpowered thinking mode: xhigh
One of the most exciting additions is a new super-powered thinking mode in GPT-5.5’s reasoning control system.
Developers can choose among these five effort levels:
- none
- low
- medium
- high
- xhigh
xhigh is effectively the “use more compute and think harder” mode, ideal for:
- architecture decisions
- subtle debugging
- security reviews
- algorithm design
- migrations
- complex planning
Instead of using maximum reasoning for every task, teams can reserve deep thinking for problems where mistakes are costly.
4. GPT-5.5 Pro variant
OpenAI also introduced GPT-5.5 Pro, aimed at users who want maximum performance.
Listed pricing:
- GPT-5.5: $5 input / $30 output per million tokens
- GPT-5.5 Pro: $30 input / $180 output per million tokens
That means Pro costs 6x more on input and 6x more on output, strongly suggesting it is designed for:
- enterprise automation
- mission-critical engineering workflows
- legal or finance review systems
- advanced research pipelines
- premium coding agents
Standard GPT-5.5 is the workhorse for everyday tasks. Pro is the high-confidence tier.
5. Greater conciseness, efficiency, and real-world speed
One of the most underrated GPT-5.5 upgrades is not raw intelligence—it is how efficiently that intelligence is delivered.
Instead of solving coding tasks with long explanations and bloated outputs, GPT-5.5 is optimized for tighter, cleaner responses that reduce both latency and cost.
In side-by-side coding tasks, GPT-5.5 reportedly uses 72% fewer output tokens than Claude Opus 4.7 to solve the same GitHub issues. Rather than generating essays, it tends to prefer concise diffs and direct fixes.
Against the previous generation, GPT-5.5 also shows stronger internal efficiency. On standard software engineering workloads (Expert-SWE), it reportedly completes tasks using 15–20% fewer tokens than GPT-5.4.
That matters because fewer tokens compound into practical gains:
- lower API cost per task
- faster iteration loops
- cleaner patches and diffs
- easier review cycles
- less noise for developers to parse
The speed gains are equally meaningful. Because GPT-5.5 generates fewer tokens while maintaining roughly GPT-5.4-level per-token latency, it can complete the same coding workloads around 40% faster in real-world use.
For developers, that means less waiting, less clutter, and more usable output.
GPT-5.5 isn’t just a routine upgrade. OpenAI is really focusing on the real pain points serious users feel every day:
- unreliable long context
- weak autonomous tool use
- shallow reasoning on hard tasks
- expensive verbosity
- lack of premium capability tiers
The result is a model that feels even more like a serious engineering collaborator.
For developers, this may be the most important upgrade of all.