How does this keep happening?
We haven’t even finished talking about how huge Gemma 4 is going to be…
And now we just got Qwen 3.6 35B — a new unbelievably tiny open-weight model that’s massively superior to Gemma 4 in so many crucial areas.
And it’s blown up massively — trillions of tokens processed just days after its release.

This thing absolutely destroyed Gemma 4 in several coding benchmarks — it’s not even close… wow.
And still FREE of course.
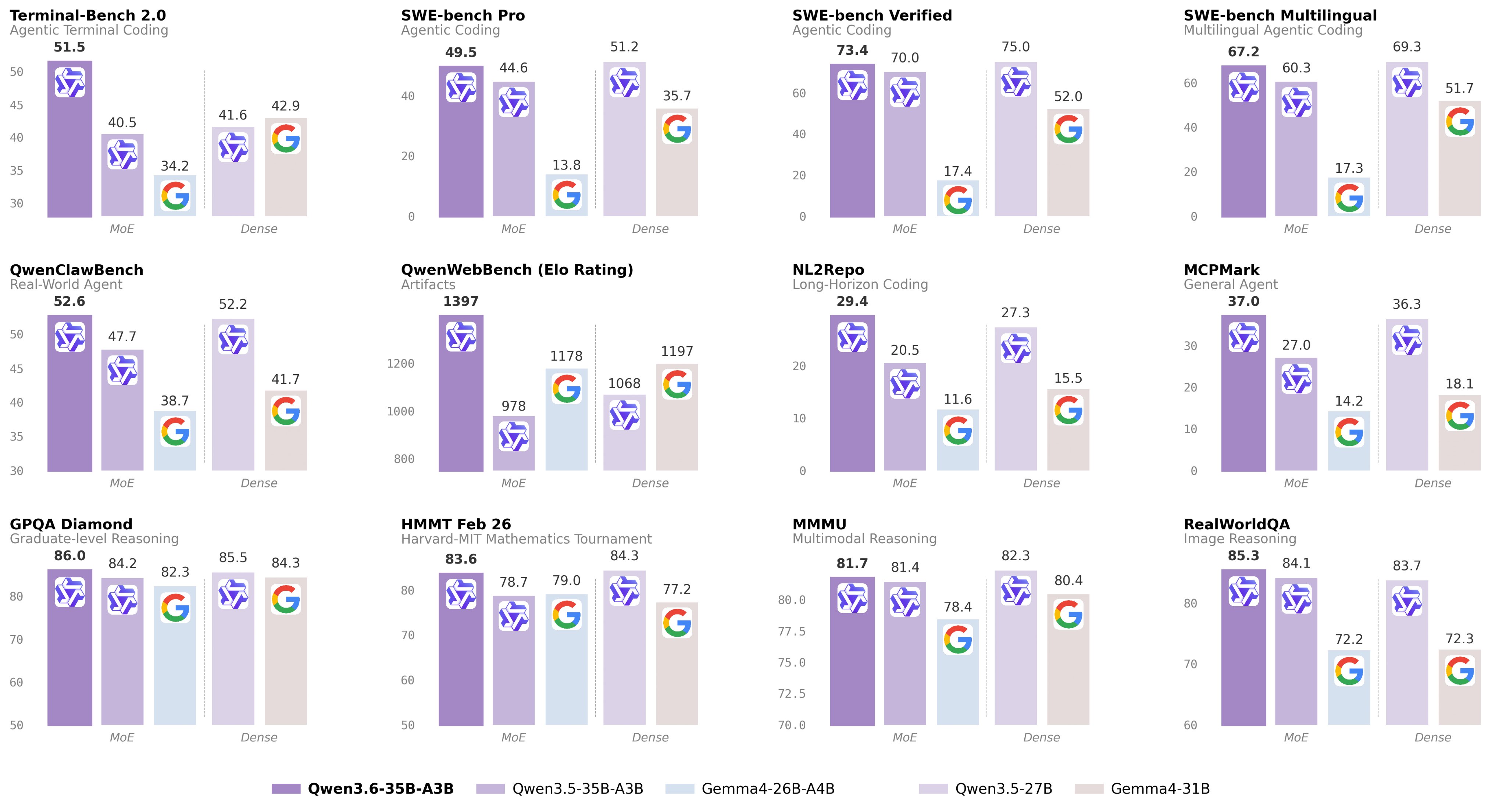
While Gemma 4 delivers a polished conversational experience, the Qwen 3.6-35B-A3B model effectively outclasses it in software engineering by solving 73.4% of real-world GitHub issues compared to Gemma’s 52.0% on the SWE-bench Verified leaderboard.
For those of you who don’t know SWE-bench is one of the most highly trusted benchmarks out there… just imagine.
And this 73.4 is so incredibly close to what Opus 4.6 scored.

Can you believe this?
This ridiculously tiny model that can run on your PC — is giving that super-computer-data-center-powered beast a dead serious run for it’s money.
Imagine how powerful this Qwen is going to be on the next release — and the next and the next…
And don’t get me started on all the other notable features like the shocking speed, the massive context… like what is this?
Gemma 4 is still struggling to get past 300K — Qwen supports a whopping 1 MILLION token context!
We’ve literally never seen an open-weight with this sort of intelligence, have this sort of processing bandwidth, it’s just incredible.
1. The most efficient model ever made
Yes — the internal design that made Gemma 4 so efficient — Qwen 3.6 takes that design to its extreme limits
It has 35 billion total parameters, but thanks to the revolutionary Mixture-of-Experts (MoE) design, it only activates 3 billion parameters per token during runtime.
Compare to Gemma 4 — that could activate 4 billion out of 26 billion parameters for its MoE model variant.
Qwen 3.6 has more total processing ability — but is much more efficient at using the exact parameters it needs to use for the task at hand.
So now you get a rare combination:
- The reasoning depth of a much larger model
- Faster inference than dense 35B models
- Lower runtime compute costs
- More realistic local deployment options
A heavyweight model without always paying heavyweight costs. “Big brain, small footprint”.
It’s really huge if you’re looking to run local workflows and save costs as a developer.
Instead of choosing between tiny fast models and giant slow models you get the awesome middle ground of Qwen.
2. Built for real coding work from the ground up
It’s not just the SWE-bench verified — Qwen 3.6 performs astonishingly in so many other coding and general AI ability benchmarks.
The upgrade over the previous version is especially notable:
- Terminal-Bench 2.0: 40.5 → 51.5
- NL2Repo: 20.5 → 29.4
All this means even better agentic capability for:
- Repository-level reasoning — understanding files, configs, and dependencies across a codebase
- Tool use — working with APIs, Python, Bash, file systems, and multi-step workflows
- Frontend workflows — generating and debugging React, UI components, CSS, and layouts
And more generally — for every aspect of software development:
- Understanding large repositories
- Editing multiple files coherently
- Fixing bugs across systems
- Using tools and terminals
- Debugging frontend issues
- Staying useful across long sessions
And so much more.
3. “Thinking preservation”
Qwen was deliberately optimized for world-class “thinking preservation”.
Most models lose their reasoning thread between turns. They forget why they made earlier decisions, repeat work, or need to re-analyze the same issue again and again.
Qwen3.6 is specifically designed to preserve reasoning context across complex conversation chains — which makes the 1 million token context window possible.
That makes a major difference for:
- Long debugging sessions
- Refactors over multiple prompts
- Multi-hour coding workflows
- Step-by-step architecture planning
- Troubleshooting where earlier context matters
4. Massive context window
Qwen3.6 technically supports a native context window of 262,144 tokens — but it’s been extended to roughly 1,010,000 tokens with sophisticated scaling methods.
That is enormous.
For us developers this means the model can potentially keep track of:
- Large repositories
- Long docs
- Logs and stack traces
- Prior conversations
- Multiple files at once
- Tool outputs and planning history
And remember: this is happening with only 3B active parameters at inference time.
It’s a technical marvel.
5. Native multimodality
This isn’t just a text model.
Qwen3.6 includes a vision encoder, meaning it can work with images and visual inputs from day one.
That opens up developer use cases like:
- Reading screenshots
- Debugging UI issues visually
- Understanding diagrams
- Parsing technical documents
- Reviewing layouts
- Frontend design workflows
Many early testers have also praised its SVG generation and visual creativity — including comparisons with proprietary frontier models in niche tasks.
This is definitely way more than just a coder
Many users are already experimenting with it on:
- Apple Silicon Macs
- Consumer NVIDIA GPUs
- High-end desktops
- Prosumer laptops
Between Gemma 4 and now this, frontier-style coding assistants just got a lot more accessible.
Qwen 3.6 35B solves several developer problems at once:
- Strong coding ability
- Efficient runtime footprint
- Long context memory
- Better agent workflows
- Visual input support
- Open weights
- Commercial-friendly Apache 2.0 license
Once again, we get to see that serious, frontier-level software agents can actually run locally and practically.
It’s be exciting to see what comes next.