
Is this it?
Is this how the AI singularity finally happens?
A model that can actually improve itself — by itself? Like even the AI researchers themselves should be worried now about losing their jobs?
MiniMax M2.7 is a self-evolving model. Let that sink in.
MiniMax M2.7 represents a fundamental shift from static training to self-evolving intelligence—an autonomous loop where the model identifies its own logic gaps and refines its own architecture, ultimately delivering frontier-class reasoning at a fraction of the cost
Look this is not about incremental intelligence improvements anymore — this is the promise (nightmare?) of endless exponential recursive self-evolving intelligence.
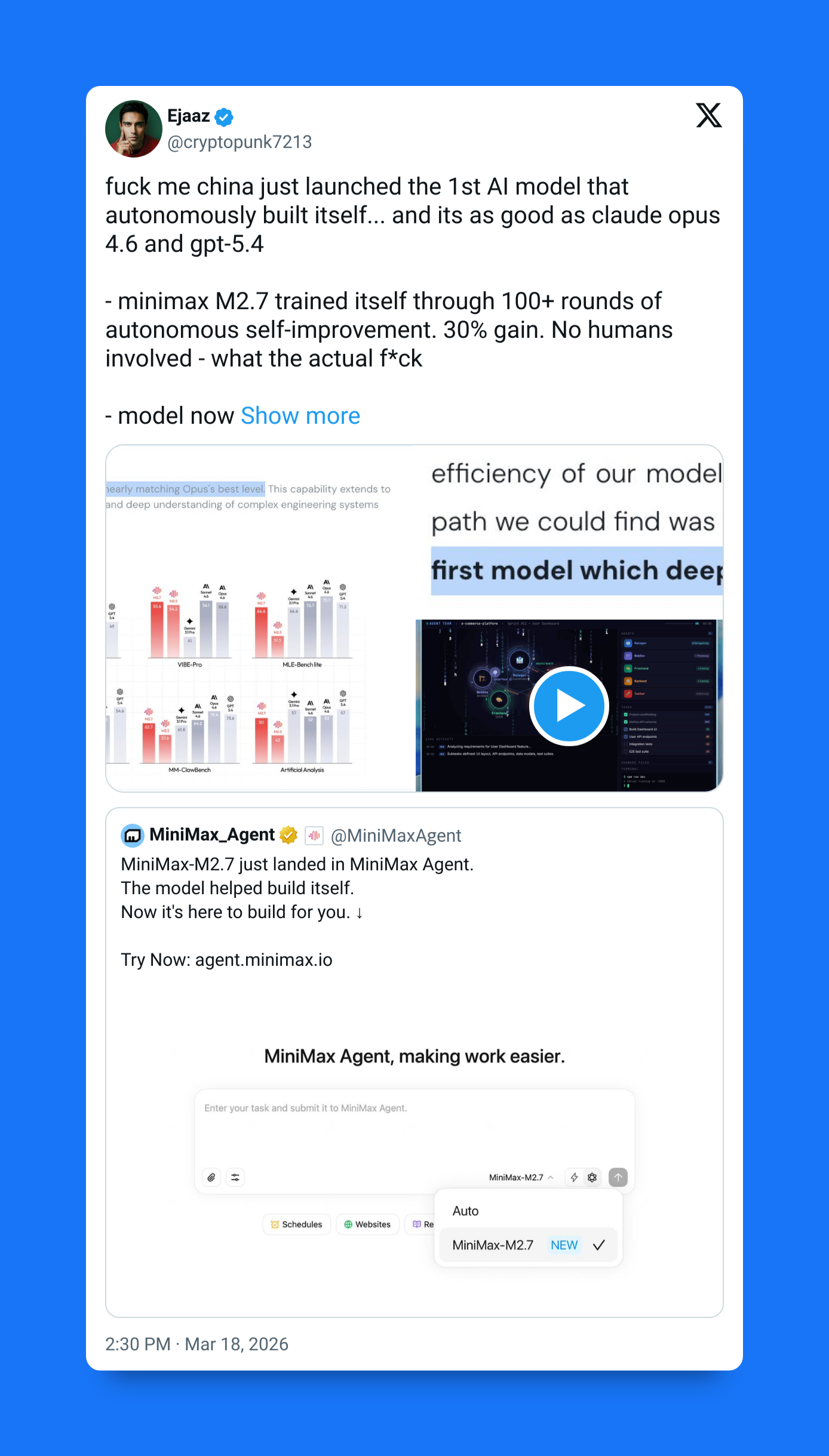
You roll your eyes and yawn (same old hype right?) — until I tenderly inform you of how MiniMax 2.7 literally handled 30-50% of its own learning research and ran 100+ iteration cycles to improve itself.
A “self-critiquing” model that can tell when it’s hallucinating? That knows when it’s not thinking straight?
By replacing human labeling with a recursive self-critique loop, MiniMax M2.7 became its own most rigorous auditor—systematically mapping its own logic gaps to drive the hallucination rate down to an industry-leading 34%.
Compare that to the possibly debatably deserved attention-grabbers of our time:
- Claude 4.6 Sonnet: 46%
- Gemini 3.1 Pro: 50%
If you’ve ever seen something as earth-shatteringly groundbreaking as this in a new model before, just let me know, okay? Because I highly doubt I have…
Instead of:
- humans design improvements
- retrain model
- repeat
You start getting:
- model proposes improvements
- model tests them
- model evaluates results
Just imagine how much faster the speed of AI progress is going to get now that the improvement is being done by AI itself.
Oh, and do I need to remind you that this is the MiniMax M series we’re talking about?
Didn’t I tell you about MiniMax M2.5 the other day? That open-source model that’s 20x cheaper than Claude models — but still just as powerful?
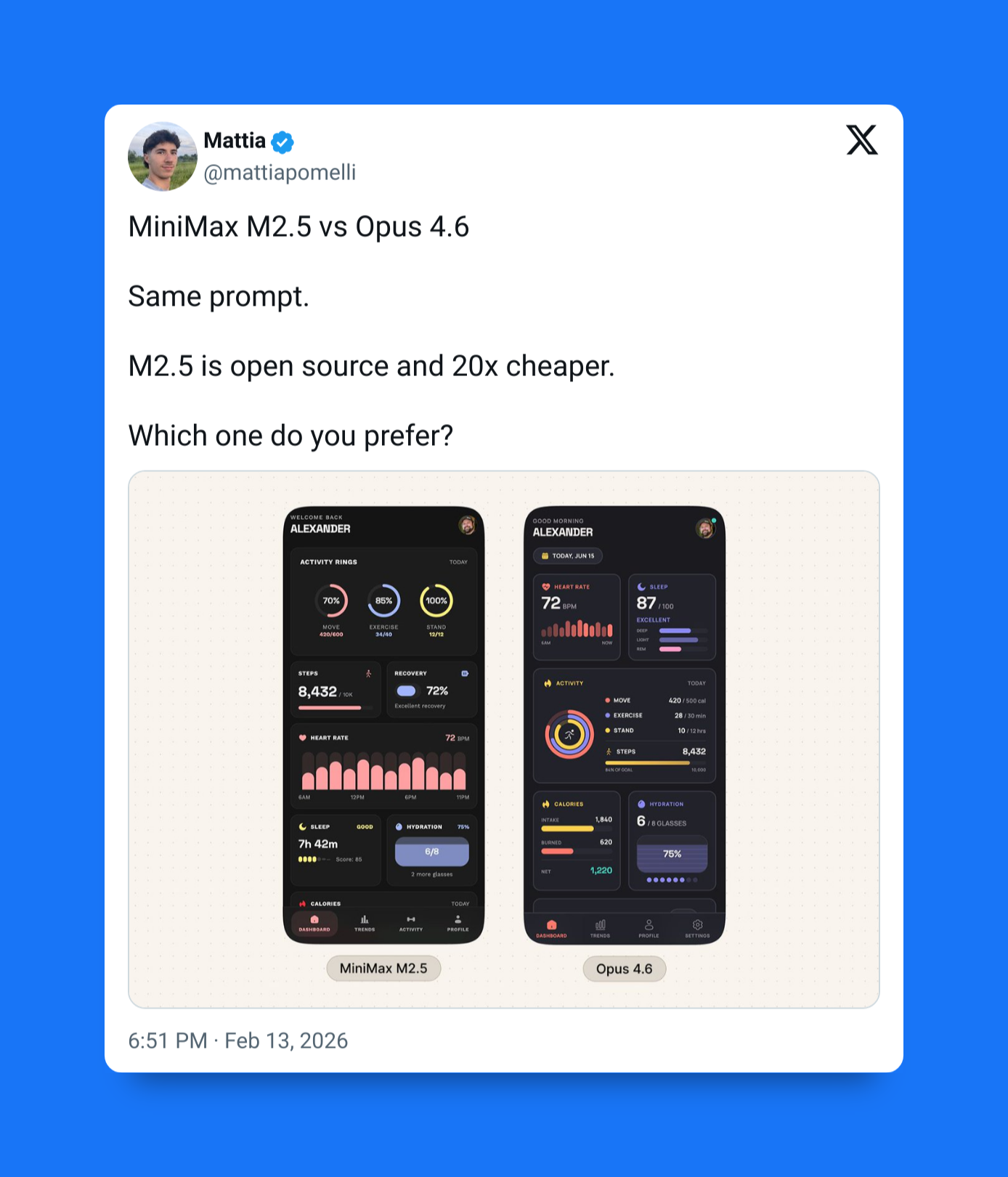
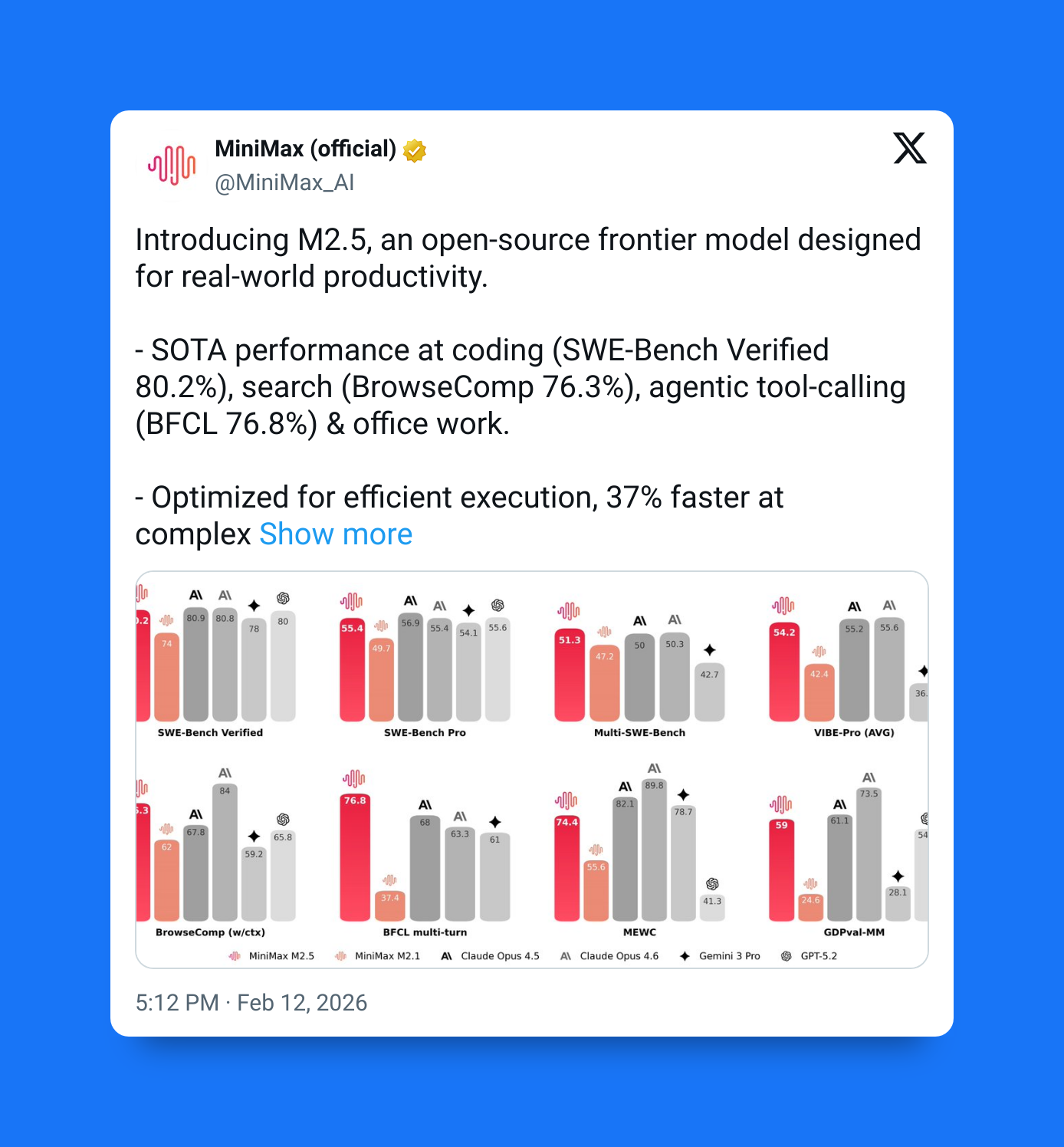
And now this is not 2.5 — this is 2.7 — do you think this is going to be worse or better than 2.5?
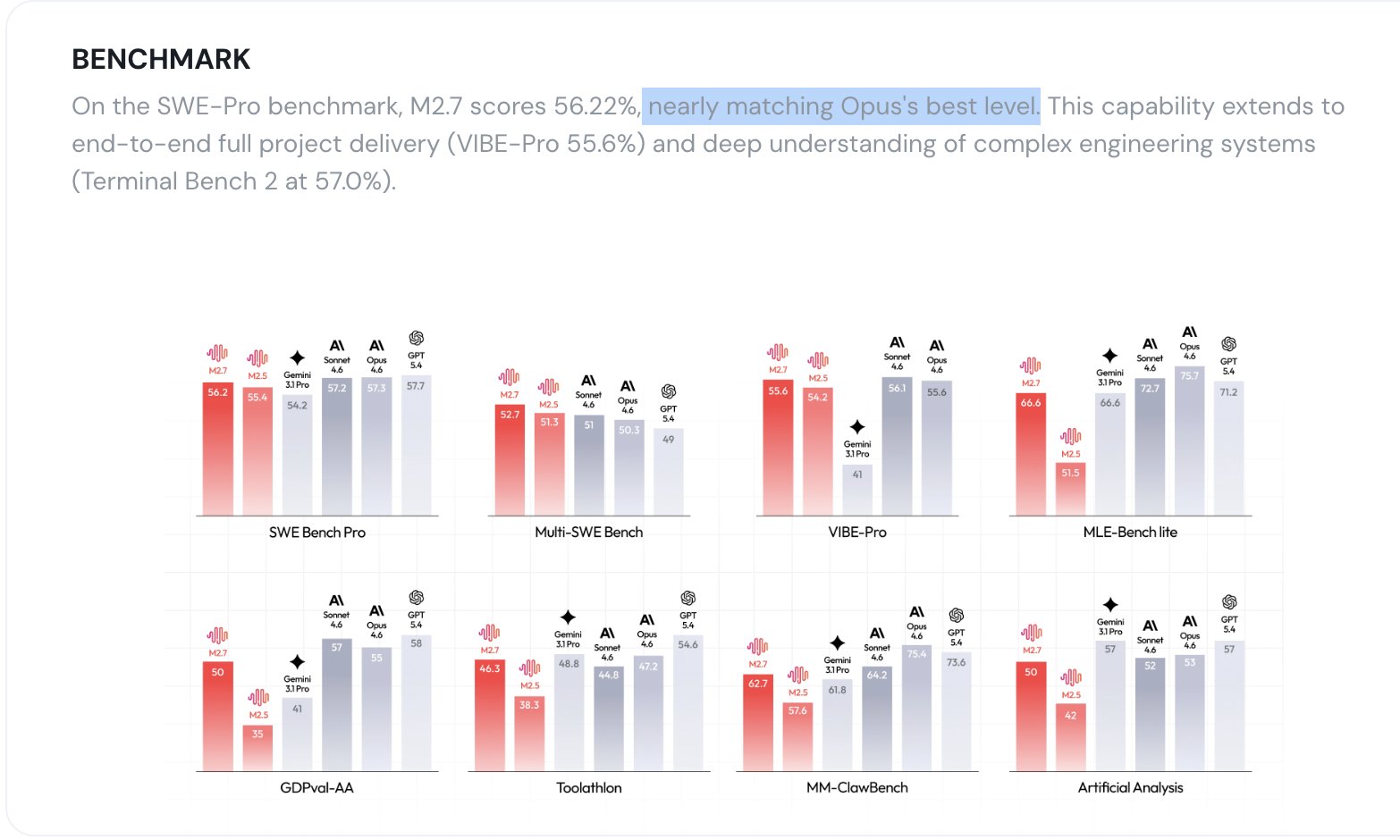
By dismantling the ‘frontier tax,’ MiniMax M2.7 delivers Opus-class intelligence at a fraction of the cost—slashing inputs to $0.30/1M and outputs to $1.20/1M—effectively making elite reasoning 16x cheaper to read and 20x cheaper to write
And I know I also told you just how blazing fast this was at an incredible 100 tokens per second — significantly faster than models like Opus.
And once again it’s not just about the raw speed — the speed per unit intelligence is what makes this such a big deal.
We have a few models that are even faster than this — but then you start comparing intelligence and it becomes a different story altogether.
Then there’s context length.
Okay fine it still only has a 200K token context — but this is still more than enough for vast majority of your projects — okay I don’t know if you work at Google or not, but still this is not nothing.
With a massive 204,800-token window, MiniMax M2.7 transforms ‘long-context’ into a functional reality—providing the cognitive room to process entire codebases, complex research, and memory-heavy agent workflows in a single, seamless sweep
So you’re looking at a model that is:
- near Opus-level capability
- ~20× cheaper
- ~massive 200K context
- 100 TPS speed
- lower hallucination rate
- partially self-improving
Economically viable + agent-ready + scalable.
The one problem right now is the open-source thing — I automatically assumed M2.7 was going to open-source like 2.5 but turns out that’s still pretty uncertain right now
M2.5 was released openly, which surprised a lot of people.
Right now, M2.7 is API-only and proprietary, and there’s no confirmation it will be open-sourced.
But MiniMax has already shown us they’re willing to do it once — so it’s definitely something to watch.
But all in all this M2.7 ain’t no joke.
We might just be teetering on the edge of an unprecedented explosion of AI progress — even much more than what we saw in 2022.
This is serious business.